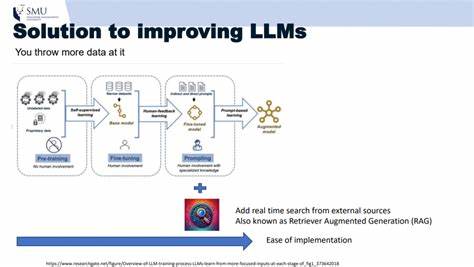
За последние несколько лет большие языковые модели (LLM) стали одним из ключевых инструментов в сфере искусственного интеллекта и обработки естественного языка. В частности, их интеграция в поисковые системы открывает перспективы значительного улучшения качества поиска и генерации ответов. Однако современные поисковые системы, основанные на LLM, зачастую жертвуют качеством ради скорости обработки запросов. Этот компромисс приводит к рискам, связанным с неточными, поверхностными и недостоверными ответами, что в свою очередь подрывает доверие пользователей и точность получаемой информации. Суть проблемы заключается в том, что традиционные LLM-усиленные поисковые инструменты стараются давать быстрые ответы, используя механизмы, которые не всегда подразумевают глубокий анализ и проверку источников.
Например, такие сервисы, как Perplexity, отличаются высокой скоростью работы, но зачастую их ответы теряют сложность и нюансы, что критично для пользователей, которые ищут достоверную и развернутую информацию. В эпоху информационного перегруза особенно важно создавать системы, которые ставят точность и доверие выше показателей быстродействия. Поначалу интуитивным решением казалось использование методов обучения с подкреплением (RL) для тонкой настройки моделей. Однако опыт показал, что одна только RL настройка без прочного фундамента в виде обучения с учителем (SFT) не обеспечивает желаемого результата. Эксперименты с моделями серии Qwen длительное время не приносили прогресса: модели испытывали сложности с выполнением базовых инструкций и не смогли справиться с разнообразием запросов и шаблонов ответов.
Более масштабные модели также не смогли полностью решить эти проблемы. Это самое важное открытие - без большого объема высококачественных данных для обучения и проверок методы RL не могут раскрыть потенциал улучшения качества выдачи. Столкнувшись с финансовыми ограничениями на генерацию подобного большого количества данных и другими затруднениями, автор перешёл к переосмыслению подхода: вместо усиленного обучения было решено сосредоточиться на оркестрации вызовов к языковой модели GPT-5 в тандеме с веб-поиском через Exa AI. Несмотря на первоначальные трудности - такие как нерелевантные или устаревшие результаты поиска и проблемные автосводки страниц - такой шаг дал ценное понимание: проблема не в самой модели LLM, а в том, как она взаимодействует с информацией и как выстроен процесс исследования данных. Поиск информации в интернете у человека не ограничивается единичным запросом.
В процессе используется множество вариаций запросов, параллельное изучение различных источников, скрупулёзное чтение и сравнение данных, а затем - синтез полученной информации. По аналогии с этим был предложен подход, основанный на реализации машины состояний, которая имитирует поведение исследователя. Первый этап - генерация запросов - предполагает создание нескольких различных, но логически обоснованных поисковых фраз, обеспечивающих широкий охват тематики. Слишком большое количество запросов приводит к поверхностному разбросу, а слишком малое количество ограничивает вариативность извлекаемой информации. Оптимальным считается создание 3-4 разнообразных и продуманных запросов.
Далее, все запросы выполняются параллельно, а результаты проходят этап ранжирования. Вместо использования штатных кратких сводок Exa AI, в работу включается специализированная лёгкая версия GPT-5, которая анализирует полные тексты страниц и формирует релевантные и понятные резюме, подчёркивая, какие данные оказались полезными для исходного вопроса, а какие нет. Этот подход позволяет избежать ошибок, связанных с неверной интерпретацией информации, и обеспечивает лучшее качество контента для последующего анализа. На заключительном этапе система интегрирует исходный пользовательский запрос и сформированные резюме, что открывает возможность построения обоснованного и прозрачного ответа. Помимо прочего, предусмотрена возможность выделения нескольких подтверждающих источников, либо выделение одного авторитетного и наиболее актуального материала.
Очень важна прозрачность: пользователю демонстрируются рассуждения модели и основания, на которых сделаны выводы. Если же доступная информация недостаточна, система честно сообщает о невозможности дать ответ, что дополнительно повышает доверие к ней. Интересным наблюдением стал показатель оптимального уровня глубины рассуждений у модели. Слишком интенсивный анализ во время генерации запросов часто порождает излишне сложные конструкции, смещая акцент и приводя к упущениям в последующих шагах. Следствие - снижение качества результата.
С другой стороны, поверхностное мышление приводит к банальному повторению исходного вопроса без расширения и уточнения. Оптимальным оказался промежуточный уровень рассуждений, обеспечивающий баланс между детальностью и продуктивностью генерации запросов. При проверке системы на известном среди специалистов Benchmark vtllms/sealqa, а именно в подмножестве seal-0 с 111 комплексными запросами, новые методы показали значительное преимущество над современными агентными системами, включая продукты OpenAI, Gemini и Grok. Точность составила около 34%, что почти вдвое лучше, чем лучшие из существующих аналогов, которые не превышали 20%. Даже с учётом спорных моментов в разметке данных этот результат отражает реальный рост качества с учётом структурированной оркестрации запросов и суждений модели.
Одним из важных преимуществ разработанной структуры является её высокая настраиваемость. Наличие множества регуляторов позволяет изменять глубину анализа, количество генерируемых запросов и объём полученных страниц на каждый запрос, что обеспечивает гибкость и возможность тонкой адаптации процесса под конкретные нужды и типы запросов. Следующими шагами для повышения точности будут реализация системы оценки уверенности приобретённой оценки и автоматическое повторное проведение поиска при неопределённости или выявлении информационных пробелов. Таким образом, цикл запрос - анализ - резюмирование - проверка будет замыкаться, улучшая качество итоговых ответов по мере серии итераций. Важно отметить, что подобная оркестрация построена без дорогостоящего обучения и использования масштабных наборов разметки.
Всего лишь за несколько дней системного инженерного анализа, без дополнительных RL-обучений, удалось достичь результатов, превзойдённых существующие решения в области LLM-усиленного поиска. Выводы очевидны: в эпоху, когда информационный шум порой затмевает факты, лучшим решением становится не непрерывное усложнение моделей, а грамотное и человекоподобное управление процессом поиска и анализа данных. Такой подход помогает повышать прозрачность и доверие пользователей, а это важно не только с технической, но и с этической точки зрения. Немного больший отклик при поиске - достойная плата за надёжность и обоснованность информации, которая имеет огромное значение в любых сферах, от науки до бизнеса и повседневных решений. Именно так, шаг за шагом, можно приближаться к созданию поисковых систем будущего с полным потенциалом больших языковых моделей, сохраняя при этом баланс между скоростью, точностью и доверием.
© 2026 Sai Praneeth, переведено и адаптировано .