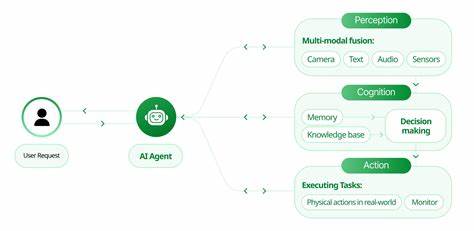
Современный мир стремительно развивается, и технологии искусственного интеллекта (ИИ) играют в этом процессе одну из ключевых ролей. С каждым годом растут требования к возможностям систем, которые должны не только понимать визуальный и текстовый контент, но и создавать на их основе новые уникальные изображения и сцены. Одним из самых ярких представителей нового поколения мультимодальных моделей является Qwen VLo — инновационная разработка, способная не просто распознавать объекты и контексты на изображениях, но и творчески воплощать их в новых визуализациях, что знаменует кардинальный сдвиг от простого «понимания» к полноценному «изображению» мира. Исторически мультимодальные модели искусственного интеллекта представляли собой системы, ориентированные на анализ и интерпретацию входящих данных в виде текста и изображений. Первые версии, включая QwenVL и его последующие обновления, показывали впечатляющие возможности в распознавании объектов и выполнении базовых задач обработки изображений.
Однако они имели ограничение — создание контента оставалось сравнительно примитивным и не всегда соответствовало сложным и разноплановым запросам пользователей. Парадигма, заложенная в Qwen VLo, претерпела качественные изменения. Модель стала объединять глубокое понимание визуального мира с емкой и многофункциональной генеративной системой, что позволило ей не только точно анализировать визуальный контент, но и преобразовывать его по запросам различных уровней сложности. Пользователи сегодня могут напрямую взаимодействовать с моделью, отправляя команды в свободной форме на китайском или английском языках, чтобы получить уникальный рисунок или изменить уже существующее изображение. Например, можно загрузить фото животного и попросить модель добавить на него шапочку или поменять фон — Qwen VLo эффективно реализует все эти задачи, сохраняя одновременно естественность и реализм результата.
Ключевая особенность Qwen VLo — прогрессивный механизм генерации изображений. Это инновационная технология, при которой картинка формируется постепенно, начинаясь с верхнего левого угла и пошагово заполняя все пространство по горизонтали и вертикали. Такой подход обеспечивает высокую детализацию и согласованность итогового изображения, а также дает пользователю возможность наблюдать ход процесса и вносить корректировки по мере необходимости. Это особенно важно для творческих задач, где нюансы и мелкие элементы играют решающую роль. Кроме того, модель демонстрирует исключительные способности в сохранении семантической целостности.
В отличие от предшественников, которые часто сталкивались с ошибками вроде неправильной идентификации объектов или искажений их формы, Qwen VLo умеет точно распознавать ключевые детали и сохранить их даже при масштабных изменениях. Например, если пользователь меняет цвет автомобиля на изображении, модель сохраняет его структуру и модель, избегая ошибок и достигая реалистичного визуального эффекта. Инструкции пользователей могут охватывать широкий спектр задач, включая стильные трансформации, добавление элементов и глубокое редактирование. Qwen VLo справляется с художественными стилями, способна имитировать знаменитых мастеров, например, стилизовать изображение под работы Ван Гога или создать эффект 19 века. Одна из лучших черт модели — открытость для многоязычного взаимодействия.
Это позволяет значительно расширить аудиторию, сделав интерфейс простым и понятным для носителей разных языков. Неважно, пользователь говорит по-английски или по-китайски, система быстро и точно реагирует на любые запросы. Qwen VLo демонстрирует возможности мультизадачности: она способна не только создавать новые изображения, но и выполнять такие сложные задачи, как сегментация объектов, предсказание краев, определение глубины сцены и многое другое. Все это достигается в рамках единой среды, что значительно облегчает интеграцию модели в разнообразные сценарии: от креативных проектов до анализа изображений для профессиональных нужд. Модель умеет эффективно комбинировать несколько инструкций, даже если они требуют многоступенчатых изменений, таких как одновременная замена фона, добавление новых объектов и стилистическое преобразование.
Это по-настоящему мощный инструмент, способный создавать сложные композиции за минимальное время и с высокой степенью точности. Примеры реальных задач, продемонстрированных на платформе, включают генерацию милых собак в различных художественных стилях, изменение деталей их образа и окружения, а также создание сложных, высокодетализированных сцен с несколькими персонажами и объектами, включающими текстовые элементы и редактируемые детали. Помимо творческой генерации, Qwen VLo предлагает расширенные функции анализа готовых изображений. Умение модели идентифицировать породы животных, выделять ключевые элементы на фото и выполнять аннотации значительно упрощает работу профессионалов в сферах дизайна, маркетинга и научных исследований. Технологии обучения с динамическим разрешением позволяют модели работать с изображениями любых размеров и аспектов, что особенно удобно для пользователей, занимающихся разными форматами – будь то веб-баннеры, постеры, иллюстрации или социальные сети.
Важной инновацией стало введение возможности управления итоговым изображением на всех этапах. Пользователи могут постранично наблюдать и корректировать визуальный процесс, что существенно повышает творческую свободу и качество результата. Несмотря на впечатляющие способности, Qwen VLo все еще находится в стадии превью и сталкивается с некоторыми ограничениями. Это вполне естественно для технологий такого уровня, особенно на начальном этапе экспансии функционала. Разработчики активно работают над повышением точности интерпретации инструкций, стабильности работы и лучшего соответствия запросам пользователей.
В будущем планируется еще больше расширить возможности модели, добавив поддержку работы с несколькими изображениями одновременно и возможность создания контента с нестандартными соотношениями сторон. Это откроет новые горизонты для дизайнеров, художников и всех, кто заинтересован в создании уникального визуального материала. Концептуально Qwen VLo представляет собой важный шаг на пути к объединению восприятия и творчества в рамках одного интеллектуального инструмента. Мультимодальные модели с генеративными функциями призваны не только отвечать на вопросы и распознавать объекты, но и становиться полноценными помощниками в визуальной коммуникации, предоставляя новые способы выражения идей и эмоций через образы. В ближайшем будущем ожидается, что такие системы смогут создавать пояснительные диаграммы, наносить вспомогательные линии и выделять важные зоны на изображениях, расширяя возможности общения человека и машины.
Это кардинально изменит ландшафт цифрового творчества и визуального взаимодействия. Более того, постоянное самосовершенствование через генерацию промежуточных результатов – таких как карты сегментации и карты обнаружения – поможет моделям улучшать свою точность и надежность, создавая замкнутый цикл обучения и контроля. Qwen VLo является одним из наиболее ярких примеров того, как новые технологии могут трансформировать наше восприятие и взаимодействие с визуальной информацией, открывая невиданные ранее перспективы для творчества, анализа и коммуникации. Интеграция понимания и генерации, поддержки мультизадачности и многоязычия делает эту модель по-настоящему универсальным и мощным инструментом, который уже сегодня способен изменить принципы работы с изображениями и текстом. Важно следить за развитием Qwen VLo и аналогичных проектов, так как они задают тренды будущего и формируют новые стандарты взаимодействия с цифровым контентом.
В эпоху, когда визуальная информация становится главным каналом коммуникации, возможности создавать, изменять и анализировать изображения быстро и качественно превращаются в неотъемлемую часть повседневной жизни и профессиональной деятельности. Таким образом, Qwen VLo не просто технологическая новинка, а символ новой эры в развитии искусственного интеллекта, где граница между восприятием и творчеством становится все более размытая, а потенциал для инноваций — безграничным.