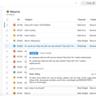
Современная индустрия машинного обучения требует всё более эффективных и масштабируемых способов подачи задач на обучение моделей. С увеличением объёмов данных и сложности алгоритмов на первый план выходят инструменты, которые позволяют автоматизировать, управлять и оптимизировать процесс тренировки моделей. В этой статье рассматриваются наиболее популярные подходы и платформы, используемые специалистами для запуска ML-задач, а также ключевые аспекты, на которые следует обращать внимание при выборе инструментов. Основное требование к средствам подачи задач на обучение связано с их масштабируемостью и надёжностью. При работе с большими датасетами и сложными моделями необходима возможность распределенного обучения, управления ресурсами вычислительных кластеров, а также автоматического контроля статуса и логирования процесса обучения.
Многие специалисты обращаются к специализированным оркестраторам и менеджерам задач, интегрированным с популярными фреймворками машинного обучения. Одним из широко распространённых подходов является использование систем управления задачами, таких как Kubernetes, в сочетании с контейнеризацией через Docker. Эти инструменты позволяют создавать изолированные и воспроизводимые окружения для обучения моделей, обеспечивают гибкое распределение вычислительных ресурсов и облегчают развертывание моделей в продакшн. Кроме того, платформа Kubernetes предоставляет механизмы автошкалирования и устойчивости к сбоям, что крайне важно при длительных тренировках. Специалисты также часто используют облачные решения, предоставляемые крупнейшими провайдерами, такими как Amazon Web Services, Google Cloud Platform и Microsoft Azure.
Эти провайдеры предлагают собственные сервисы для обучения моделей, которые включают интеграцию с сервисами хранения данных, гибкое управление вычислительными мощностями и инструменты мониторинга. Облачные сервисы позволяют легко масштабировать задачи обучения и оплачивать ресурсы по факту использования, что выгодно при переменных нагрузках. Немалую популярность приобретают фреймворки и платформы, специализированные именно на машинном обучении. Среди них выделяются Kubeflow, MLflow, Apache Airflow, а также более узконаправленные инструменты вроде Ray Tune для гиперпараметрической оптимизации. Kubeflow, например, интегрируется с Kubernetes и предоставляет полноценный набор компонентов для построения конвейеров машинного обучения, включая подготовку данных, обучение, тестирование и деплоймент моделей.
MLflow же направлен на управление жизненным циклом моделей, включая отслеживание экспериментов и регистрацию артефактов. Нельзя забывать и про традиционные менеджеры очередей задач, такие как Celery или Apache Kafka, которые в определённых сценариях применяются для распределения вычислительной нагрузки и построения масштабируемых систем обработки обучения. Они удобны для управления независимыми задачами и интеграции с системами мониторинга и логирования. Огромное значение при выборе инструмента имеет удобство разработки и поддержки. Не все платформы обладают простым интерфейсом, поэтому зачастую специалисты создают собственные оболочки и скрипты, интегрирующие разные компоненты в единый конвейер.
При этом важно обеспечить прозрачность процесса работы, чтобы можно было отслеживать статус запуска, успехи и ошибки задач, а также эффективно использовать результаты для дальнейшей оптимизации моделей. Кроме того, вопрос стоимости и доступности ресурсов остаётся критичным. Использование собственных кластеров требует значительных инвестиций в оборудование и поддержку, тогда как облачные решения значительно упрощают старт и развитие проектов, но могут создавать непредвиденные расходы при недостаточном контроле. Именно поэтому многие компании прибегают к гибридным стратегиям, совмещая локальные вычислительные мощности с облачной инфраструктурой. Важен и аспект безопасности при работе с конфиденциальными данными.
Платформы должны обеспечивать правильную аутентификацию, шифрование передачи данных и управление доступом к вычислительным ресурсам и хранилищам. Законодательные ограничения в разных регионах также влияют на выбор инструментов и архитектуру решений. Наконец, нельзя обойти вниманием новые тренды, такие как серверлесс-архитектуры для Machine Learning или интеграция с системами непрерывной интеграции и доставки (CI/CD). Они открывают ещё большие возможности по автоматизации жизненного цикла моделей и сокращению времени вывода продуктов на рынок. Таким образом, выбор инструмента для подачи и управления задачами обучения машинного обучения зависит от множества факторов: масштаба проектов, бюджета, требований к скорости итерации, безопасности и удобству эксплуатации.
Важно учитывать экосистему, в которой работает команда, её навыки, а также возможности расширения и интеграции с другими системами. В итоге грамотный подбор инструментов способствует ускорению научно-исследовательских и прикладных разработок, повышая качество и эффективность разрабатываемых моделей.