Развитие искусственного интеллекта открыло новые горизонты в обработке и анализе данных, особенно в таких критически важных сферах как работа с базами данных. Технология Text-to-SQL стала одним из самых востребованных решений, позволяющих преобразовывать текстовые запросы на естественном языке в корректные SQL-запросы, что значительно упрощает доступ к структурированной информации даже для пользователей без глубоких навыков в программировании. Недавно компания Contextual AI представила в открытый доступ свою локальную систему Text-to-SQL, которая демонстрирует выдающиеся результаты по версии популярного бенчмарка BIRD, доказывая, что локальные решения могут конкурировать с крупнейшими API с использованием моделей таких гигантов, как Gemini и GPT-4o. Эта система обладает уникальным потенциалом как для обеспечения безопасности критически важных данных, так и для гибкой кастомизации, что делает ее привлекательной для современного бизнеса и исследований. Рассмотрим, почему локальные модели Text-to-SQL стали ключевым направлением в области обработки данных и как инновационная система Contextual-SQL реализует передовые методы для достижения впечатляющих результатов.
В современных организациях большая часть оперативных данных хранится в структурированных базах — финансовые отчеты, данные о клиентах, инвентарные показатели. Доступ к ним требует знаний SQL, являющегося универсальным языком запросов к реляционным базам данных, что создает технологические барьеры между специалистами в бизнесе и IT-отделами. Text-to-SQL системы устраняют этот разрыв, автоматически преобразуя естественно-языковые запросы пользователей в исчерпывающий и точный SQL-код, что экономит время и упрощает получение бизнес-аналитики без посредников. Открытое программное обеспечение от Contextual AI подчеркивает важность работы локальных моделей в условиях, когда данные часто содержат конфиденциальную информацию, такую как финансовые транзакции и персональные сведения клиентов. В отличие от закрытых API, локальные модели работают на оборудовании предприятия, не покидая защитную инфраструктуру, что снижает риски утечек и нарушений конфиденциальности.
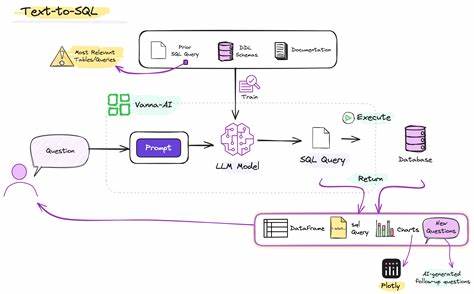
Дополнительным преимуществом является возможность кастомизации и адаптации моделей под специфические отраслевые задачи, что невозможно в традиционных облачных сервисах. В основе Contextual-SQL лежит инновационная двухэтапная архитектура, где на первом этапе система генерирует множество вариантов SQL-запросов на основе предоставленного контекста, а затем тщательно отбирает и ранжирует лучшие кандидаты для исполнения. Эта схема позволяет не только повысить разнообразие решений на этапе генерации, но и использовать сложные методы оценки качества запросов, включая проработку выполненности SQL и обучение дополнительной модели, которая присваивает кандидатам оценку с учетом правильности результатов. Ключевая особенность успешности системы Contextual-SQL — качество и полнота контекста. Входные данные для модели включают подробное описание структуры базы данных, представленное с помощью Data Definition Language (DDL) и mSchema — усовершенствованного текстового формата, основанного на SQLAlchemy и дополненного информацией о связях между таблицами и примерах содержимого столбцов.
Такой формат позволяет модели лучше понять архитектуру данных и устанавливать правильные связи при формировании запросов. Добавление демонстрационных примеров запросов и ответов в рамках техники few-shot learning дополнительно улучшает производительность и точность генерации. Еще один ключевой фактор — масштабирование вычислений во время инференса. Исследования показывают, что увеличение количества вариантов генерируемых кандидатных запросов и последующий выбор лучших с помощью специализированных алгоритмов значительно повышают показатель pass@k — вероятность получения по крайней мере одного корректного SQL из k сгенерированных вариантов. Contextual AI реализует эти принципы за счет многократного параллельного запуска генерации с разнообразными подсказками на входе и повышенной температурой выборки, что способствует появлению разнообразных и релевантных вариантов.
Для отбора среди множества кандидатов создается специализированная модель-оценщик (reward model), обученная отличать корректные SQL-запросы от ошибочных, основываясь на их фактическом выполнении и соответствии эталонным результатам из обучающей выборки BIRD. Совмещение логарифмического вероятностного значения запроса (лог-проб) с оценкой reward model позволяет обеспечить высокий уровень надежности отбора среди множества вариантов. В практическом плане такая система обеспечивает предприятиям гибкие инструменты для эффективного взаимодействия с собственными данными без компромиссов с точки зрения безопасности и производительности. Открытая система уже доступна на GitHub и включает подробный Colab ноутбук с инструкциями по запуску и экспериментам, что существенно облегчает внедрение и адаптацию. Однако вызовы остаются масштабнее простой генерации одиночных запросов.
Предприятия сталкиваются со сложными схемами баз данных с тысячами таблиц и колонок, необходимостью выполнять многоступенчатые запросы и поддерживать различные диалекты SQL. Новый бенчмарк SPIDER 2.0 именно это и отражает — он включает реальные сценарии из множества отраслей с высокими требованиями к контексту и вычислительным ресурсам. Несмотря на меньшую производительность топовых моделей на SPIDER 2.0 по сравнению с предшествующей версией, открытая система Contextual AI предлагает прочную основу для дальнейших исследований и доработок, направленных на масштабирование и углубленную обработку.
Перспективы развития локальных Text-to-SQL систем связаны с интеграцией методов параллельной обработки, применением усиленного обучения, оптимизацией создания кандидатов и расширением возможностей по обработке сложных SQL-запросов. Кроме того, программные решения, работающие непосредственно на территории компаний, открывают дверь для разработки кастомных бизнес-логик, специфичных автотестов и интеграций в общие инструменты аналитики и BI без зависимости от внешних поставщиков. В итоге опыт Contextual AI показывает, что локальные модели Text-to-SQL при правильной архитектуре и технической реализации могут успешно конкурировать с ведущими API-решениями, предоставляя не только высокую точность и гибкость, но и решая ряд проблем конфиденциальности и адаптивности. Это особенно актуально в эпоху стремительного роста требований к безопасности данных и персонализации корпоративных AI-инструментов. Появление на рынке такого открытого локального решения способствует ускоренному развитию сферы, позволяя исследователям и разработчикам адаптироваться под специфические бизнес-кейсы и способствуя повышению качества взаимодействия с корпоративными данными.
Система Contextual-SQL утверждает новый стандарт в области Text-to-SQL, демонстрируя баланс между инновациями алгоритмов и практическими требованиями современных предприятий. Ожидания на будущее связаны с устранением барьеров масштабируемости, интеграцией с многоступенчатыми и кросс-диалектными SQL-процессами, а также внедрением методов самообучения и самокоррекции моделей. Также развитие сферы Text-to-SQL напрямую связано с общим прогрессом в NLP и вычислительных технологиях, а предоставление открытых инструментов формирует мощную экосистему для специалистов, стремящихся преобразовывать данные в знания с максимальной эффективностью и безопасностью. Эта технология обещает стать мощным катализатором цифровой трансформации корпоративного сектора и аналитики данных в ближайшие годы.