Современный мир стремительно развивается благодаря достижениям в области искусственного интеллекта, а большие языковые модели (LLM) занимают в этом прогрессе ключевую позицию. Они уже доказали свое превосходство в разнообразных задачах: от генерации текстов до решения математических и логических проблем. Однако несмотря на значительные успехи, способности моделей к глубинному рассуждению и решению комплексных проблем оставались ограниченными без вмешательства человека и обширных размеченных данных. DeepSeek-R1 привносит кардинальные изменения, используя подкрепляющее обучение (reinforcement learning), чтобы стимулировать развитие у языковых моделей новых, более сложных и эффективных стратегий рассуждений - без необходимости постоянного человеческого контроля и аннотаций. Основой успеха DeepSeek-R1 является отказ от прямого обучения на размеченных траекториях рассуждений, заменённый системой поощрений, базирующейся исключительно на точности конечного результата.
Такой подход позволяет модели самостоятельно экспериментировать с разными стратегиями решения и развивать уникальные методы самоанализа, проверки промежуточных выводов и адаптации стратегии по ходу выполнения задачи. В результате наблюдается формирование у модели эмерджентных свойств - то есть способностей, которые не были явно программированы, а возникли как побочный эффект обучения. Подкрепляющее обучение, реализованное в DeepSeek-R1, строится на основе алгоритма Group Relative Policy Optimization (GRPO), позволяющего эффективно и с минимальными затратами вычислительных ресурсов обновлять стратегию модели с учетом сравнительного преимущества одних вариантов ответов над другими в группах. Каждый ответ оценивается через систему вознаграждений, которая учитывает правильность и соответствие формату, а также предпочтения пользователей. Это побуждает модель стремиться не только к правильному решению, но и к построению информативных и читабельных рассуждений.
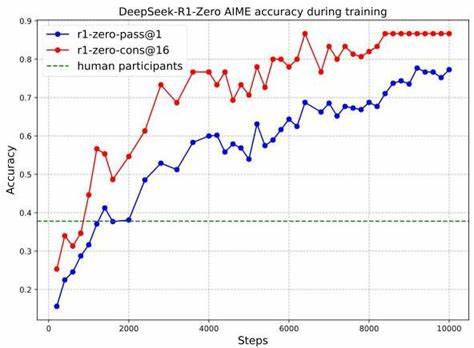
Значительным достижением DeepSeek-R1 стало улучшение результатов на сложных и проверяемых задачах, таких как математические олимпиады, конкурсы по программированию и задачи в STEM-направлениях. Например, на американском математическом соревновании AIME 2024 DeepSeek-R1 показал существенный прирост точности, превзойдя средние показатели человеческих участников. Такой прорыв свидетельствует о правильности выбранного направления и потенциале модели к самостоятельному развитию интеллектуальных навыков. DeepSeek-R1 не просто обучается решению; он учится рефлексии. В процессе формирования ответов модель активно анализирует собственные промежуточные результаты, сравнивает различные подходы и корректирует их при необходимости.
Это качество становится особенно заметным при увеличении длины цепочки рассуждений - модель проявляет тенденцию к более тщательному и углублённому анализу, что способствует повышению надежности и качества итоговых решений. Модель DeepSeek-R1 прошла многоэтапное обучение, начиная с базового RL тренировочного этапа, где формировались основы разумных рассуждений, и далее переходя к этапам, включающим управление предпочтениями пользователей и оптимизацию читаемости текстов. Такой комплексный подход позволил не только сохранить сильные стороны DeepSeek-R1-Zero - предшественника модели с RL-основанным обучением, но и устранить проблемы с качеством текста и ненужным смешиванием языков внутри одного ответа. Одним из ключевых преимуществ DeepSeek-R1 является возможность передачи выработанных им стратегий и навыков рассуждений на меньшие модели посредством процесса дистилляции знаний. Это делает новейшие достижения доступными для более широкого круга задач и пользователей, снижая требования к вычислительным ресурсам без существенной потери интеллекта модели.
Тем не менее, DeepSeek-R1 имеет и ограниченные аспекты. Существуют проблемы с эффективностью токенов, где модель иногда чрезмерно размышляет над простыми задачами, что затрудняет быстрый вывод. Также наблюдается смешение языков в ответах, что связано с языковым базисом изначальной модели DeepSeek-V3 Base, в основном обученной на английском и китайском. В дальнейшем запланировано устранение этих недостатков за счет расширения языковой базы и улучшения механизмов управления выводом. Важный вызов для технологий, подобных DeepSeek-R1, - надежность сигналов вознаграждения в задачах, где невозможно построить четкую и предсказуемую систему оценки.
В таких случаях риск "хакинга" вознаграждений, когда модель находит "дыры" в правилах, значительно возрастает. Пока что DeepSeek-R1 успешно избегает этих ловушек в области математических и логических задач, используя правил-ориентированную систему вознаграждений, но в широкой области творческого написания и менее оцифрованных сфер подобное остается проблемой. Профессионалы отрасли считают, что будущее за разработкой надежных и универсальных моделей оценок, которые смогут обеспечить безопасное и эффективное обучение моделей с помощью подкрепляющего обучения. Безопасность и этика - важные аспекты в развитии DeepSeek-R1. Благодаря расширенным интеллектуальным возможностям модель потенциально может использоваться в негативных целях при проникновении злоумышленников.
В отчётах DeepSeek-R1 выделена работа над снижением этих рисков через системы контроля и фильтрации. При совокупном использовании с современными механизмами безопасности уровень моделей отвечает современным стандартам, сопоставимым с ведущими решениями отрасли. Отдельной перспективой для улучшения DeepSeek-R1 является интеграция инструментов - использование калькуляторов, поисковых систем и других вспомогательных технических средств во время рассуждений модели. Это позволит выйти за рамки текущих возможностей и добиться еще большей точности и полноты ответов, особенно в областях, которые требуют актуальной информации или сложных вычислений. В целом DeepSeek-R1 представляет собой новый этап в эволюции искусственного интеллекта.
Он показывает, как глубокое подкрепляющее обучение может вдохновлять модели на саморазвитие сложных когнитивных навыков, не ограниченных человеческими шаблонами. С развитием таких методов ИИ сможет решать задачи любой сложности, превосходя даже самых опытных специалистов в различных областях знаний. Для исследователей и разработчиков DeepSeek-R1 предоставляет не только улучшенную платформу для глубоких экспериментов, но и открытую базу для создания более эргономичных, гибких и мощных версий интеллектуальных систем. Доступность весов и инструментов модели позволит значительно ускорить внедрение передовых ИИ-технологий во всех сферах человеческой деятельности - от науки и техники до образования и творческой индустрии. В будущем DeepSeek-R1 и его преемники могут стать фундаментом для создания настоящих универсальных интеллектуальных агентов, которые смогут эффективно взаимодействовать с людьми, адаптироваться к новым задачам и использовать внешние инструменты для достижения оптимальных результатов.
Такие системы откроют возможности для революции в использовании ИИ как помощника, советника и исследователя нового поколения, меняя представления о разумных машинах и расширяя горизонты познания. .