В современном мире искусственный интеллект активно развивается, становясь неотъемлемой частью повседневной жизни и профессиональной деятельности. Одной из ключевых задач этой области является создание систем, способных не только обрабатывать текст, но и выполнять сложные интеллектуальные операции, включая рассуждение, логический анализ и решение комплексных задач. DeepSeek-R1 - одна из последних разработок в сфере больших языковых моделей (LLM), которая открывает новые горизонты в стимулировании и развитии способности моделей вести продуманное рассуждение с помощью обучения с подкреплением. До появления DeepSeek-R1, задачи, связанные с рассуждением, в основном решались с опорой на методы, требовавшие больших объемов вручную аннотированных данных, а также симуляции цепочек мышления (chain-of-thought prompting). Эти подходы заметно повысили производительность моделей на некоторых сложных задачах, но они имели ряд существенных ограничений.
Прежде всего, зависимость от человеческих примеров сковывала возможности модели, не позволяя ей исследовать нестандартные и более эффективные способы рассуждения, а также усложняла масштабирование таких систем из-за больших затрат на аннотирование. DeepSeek-R1 кардинально меняет этот подход, переходя к использованию обучения с подкреплением (reinforcement learning - RL) для формирования навыков рассуждения. Отказавшись от необходимости прямого обучения на человеко-метках, модель получает стимулы, исходя из корректности конечных результатов, что способствует развитию новых, более сложных стратегий решения задач. Ключевым преимуществом данного метода является его способность стимулировать появление таких продвинутых функций, как саморефлексия, проверка промежуточных шагов и адаптация стратегии во время рассуждений. Обучение с подкреплением в DeepSeek-R1 построено на группе методов, включая улучшенный алгоритм Group Relative Policy Optimization (GRPO).
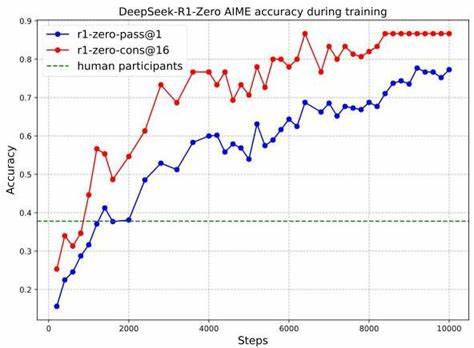
Данный подход облегчает оптимизацию политики поведения модели, делая её обучение не только эффективным, но и масштабируемым. Такая архитектура дает возможность модели постепенно создавать развернутые цепочки мыслей, включающие варианты альтернативных решений, а также промежуточные проверки, что существенно повышает качество и достоверность выводов. Появление DeepSeek-R1-Zero - базовой версии модели - стало важной вехой в процессе, демонстрирующей значительный рост точности в задачах высокого уровня сложности. На примере конкурса AIME 2024 достигнута точность порядка 78% на первом выводе и более 86% при использовании техники согласованности ответов. Подобные результаты значительно превышают средние показатели человеческих участников, подтверждая эффективность методики RL для укрепления навыков рассуждения в LLM.
Однако, DeepSeek-R1-Zero показала и определённые недостатки, в числе которых сложности с читаемостью и языковое смешение. Эти проблемы связаны с характером исходного набора данных, где преобладают английский и китайский языки. Также модель демонстрировала ограниченную универсальность, сужаясь в рамках определённых задач, в то время как общие навыки, такие как составление текстов или ответы на широкие запросы, оставались на среднем уровне. Для преодоления этих вызовов была разработана усовершенствованная версия - DeepSeek-R1, включающая многоэтапную обучающую процедуру. Здесь применяется интеграция методов отборочного сэмплинга, дополнительного обучения с подкреплением и дообучения с использованием человеко-аннотированных данных (supervised fine-tuning).
В результате модель смогла не только сохранять выдающиеся способности к рассуждению, но и достигать высокого уровня согласованности в языке ответов, а также улучшать навыки взаимодействия с пользователями. Данный мультиэтапный процесс позволил DeepSeek-R1 превзойти предыдущие результаты, как в специализированных дисциплинах - математике, программировании и STEM направлениях, так и в задачах общего инструкционного характера. Например, прирост показателей оценок на MMLU, AlpacaEval и других широко признанных бенчмарках демонстрирует сбалансированное сочетание интеллектуальной глубины и адаптивности. Это особенно ценно для применения LLM в реальных сценариях, требующих не только точности, но и дружелюбия к пользователю. Одним из уникальных аспектов модели является естественное выделение и прогрессивное усложнение цепочек рассуждений.
В процессе обучения DeepSeek-R1 демонстрирует расширение длины своих ответов, что указывает на увеличение "времени размышления". Этот показатель коррелирует с улучшением качества выводов - система самостоятельно разрабатывает стратегии проверки, переосмысления, корректировки ошибок и даже генерирует моменты "озарения". Эти наблюдения подтверждают гипотезу о том, что обучение с подкреплением может стать эффективным способом развития истинного искусственного интеллекта, ориентированного на глубинное понимание и адаптацию. Несмотря на все достоинства, DeepSeek-R1 подвержена ряду ограничений и рисков. К числу проблем относится повышенная чувствительность модели к качеству и форме входных запросов, что обязывает к тщательной настройке подсказок (prompt engineering).
Кроме того, присутствует проблема излишней генерации лишних рассуждений ("overthinking") на простых задачах, что снижает эффективность использования токенов. Важным моментом является и языковое смешение в ответах, что связано с полилингвальной природой обучающих данных. В настоящее время DeepSeek-R1 оптимизирована преимущественно для английского и китайского языков, что ограничивает её универсальность и требует дополнительной работы по улучшению поддержки других языков. Безопасность и этика также занимают центральное место в развитии технологии. С появлением мощных моделей возрастает риск злоупотребления как за счет возможного обхода защитных механизмов, так и из-за возможности изготовления вредоносного контента с использованием усовершенствованных рассуждений.
DeepSeek-R1 прошла комплексные тесты по безопасности, показав средний уровень защиты, сравнимый с аналогами мирового уровня. Однако, учитывая открытый характер моделей, необходимы дополнительные меры и постоянный мониторинг для минимизации потенциальных угроз. В плане развития технологий, будущие версии DeepSeek предполагают интеграцию инструментов и сервисов, которые позволят расширить функционал моделей. Это могут быть подключаемые вычислительные инструменты, системы поиска информации, а также интеграция с реальными объектами проверки, например, в научных экспериментах. В целом DeepSeek-R1 демонстрирует, что обучение с подкреплением является перспективной стратегией для повышения интеллектуального потенциала больших языковых моделей.
Это открывает новую эру в развитии ИИ, где отсутствие жёстких инструкций со стороны человека компенсируется динамическим самосовершенствованием через взаимодействие с окружающей средой и объективной обратной связью. Такая парадигма сулит создание систем, способных превосходить человеческую производительность в ряде сложных интеллектуальных задач, от математики и программирования до комплексного анализа и принятия решений. В заключение, DeepSeek-R1 - это не только технологический прорыв, но и важный шаг на пути к созданию по-настоящему адаптивных и самосовершенствующихся интеллектуальных систем. Несмотря на имеющиеся вызовы, эти модели предоставляют надежную основу для дальнейших исследований и широкого внедрения в различные сферы, делая искусственный интеллект более мощным, эффективным и полезным для общества. .