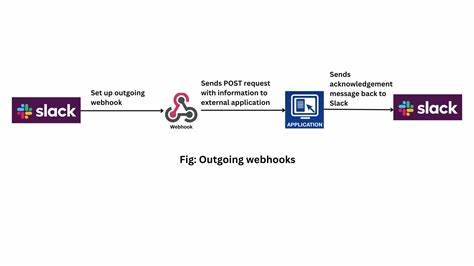
В мире современных цифровых продуктов и сервисов обмен событиями между различными системами становится повседневной задачей. Внутренние вебхуки, представляющие собой автоматизированные HTTP-запросы, позволят отслеживать ключевые события продукта, состояния серверов, результаты интеграций с третьими сторонами. Однако при неправильной организации поток уведомлений возникает одна типичная и закономерная проблема — спам в каналах Slack, что затрудняет поиск нужных данных и снижает продуктивность коммуникации команды. В такой ситуации важно подобрать эффективный подход к фильтрации, маршрутизации и управлению уведомлениями, чтобы сохранить контроль над информационным потоком, не потеряв при этом важные события. Рассмотрим основополагающие принципы и успешные методики работы с внутренними вебхуками без излишней нагрузки на Slack и другие коммуникационные платформы.
Неправильная организация уведомлений может не только мешать концентрироваться на текущих задачах, но и привести к пропуску важных сигналов, так как сообщения быстро смешиваются с обычным общением, а поиск необходимых уведомлений становится долгим и неудобным. Кроме того, беспорядочный приход многочисленных вебхуков создает впечатление хаоса даже в небольших командах, где коммуникации и так достаточно ограничены. Естественная склонность разработчиков использовать Slack для всех видов оповещений порождает «шумиху», которая противоречит самому назначению платформы — эффективному обмену информацией и поддержке оперативной связи. Прежде чем приступить к техническим решениям, важно понять, какие именно события необходимо контролировать и с какими целями. Внутренние события могут включать информацию о новых пользователях, апгрейдах, обновлениях продукта, результатах фоновых задач, успешных или неудачных миграциях блочной архитектуры, состоянии систем безопасности, а также отчетах сторонних сервисов вроде SEO-аналитики.
Все эти уведомления имеют разную степень критичности и приоритетность, поэтому ожидание одинакового внимания к ним от всей команды необоснованно. Более того, ряд сообщений пытается просто повысить общую осведомленность, тогда как некоторые отражают потенциально критичные сбои или сбои в работе. Следует принять за основу разделение уведомлений по категориям и уровню важности, чтобы информировать нужных людей, а не всех подряд. В ситуации с одиночным разработчиком или мини-командой, где использование специализированных систем мониторинга кажется чрезмерным и затратным, может помочь грамотная маршрутизация сообщений в отдельные каналы или даже сторонние хранилища с визуализацией, которые позволят отслеживать события без нарушения продуктивного рабочего пространства Slack. Известны случаи, когда организации создавали отдельные каналы по темам внутреннего мониторинга вместо объединения всего в один.
Таким образом, поток сообщений становится осмысленнее и легче поддаётся фильтрации. Например, канал с отчетами по обновлениям продукта, отдельный сбоев в бэкенде и отдельный — операций сторонних сервисов. Кроме того, внутри Slack можно задействовать возможности встроенного поиска, фильтров, закрепления ключевых сообщений и настройки уведомлений, чтобы минимизировать избыточность и не отвлекать участников на несущественные события. Важно рассмотреть использование интеграций с внешними платформами, адаптированными для сбора, хранения и анализа уведомлений. Например, сервисы вроде Bugsink специализируются на упрощенном мониторинге и позволяют настроить Slack-нотификации конфигурируемого характера без перегрузки каналов.
Такие решения часто предлагают удобные дашборды, возможность реакции на события по группам и приоритетам, что облегчает контроль за состоянием продукта и систем. Если рассматривать варианты хранения и инструментов вне Slack, альтернативой может стать использование баз данных, специализированных таблиц или платформ для совместной работы вроде Airtable и Notion. В них можно организовать централизованный сбор уведомлений с возможностью категоризации, тегирования, комментариев и долгосрочного хранения исторических данных. Такой подход позволяет сильно повысить управляемость информацией без массовой рассылки и нагрузки на коммуникационные каналы. Для собственных решений существует возможность разработать лёгкий внутренний дашборд с веб-интерфейсом, который по вебхукам будет отображать собранные события с фильтрами и сортировками.
Такой дашборд сможет стать единым местом контроля без необходимости просмотра Slack-каналов и почты. При организации своей системы рекомендуется сразу разработать правила, какие события и при каких условиях будут отправляться в Slack, а какие — сохраняться для периодической проверки. Для приоритетных и критичных уведомлений Slack обладает хорошей функциональностью по кастомизации звуков, визуальных сигналов и каналов доставки. Но менее срочные сообщения лучше перебрасывать в отдельные сервисы или копить в дневных или недельных отчетах, что позволит разгрузить ленту и улучшить восприятие информации. Большую роль играет также культура использования и обучение команды правильному отношению к уведомлениям.
Определение стандартов, когда уведомлять и что можно пропустить, поможет избежать психологической усталости и снизит вероятность пропуска значимых сигналов. Подводя итог, основными моментами эффективного управления внутренними вебхуками являются четкое распределение событий по важности, использование отдельных каналов по категориям, применение специализированных инструментов и платформ для мониторинга, а также создание собственной системы визуализации при необходимости. Соблюдение этих правил поможет существенно повысить информативность и снизить уровень шума, обеспечивая прозрачность процессов без ущерба для команды и продукта. Таким образом, любой разработчик или команда, даже очень маленькая, сможет организовать внутренние уведомления так, чтобы они приносили пользу, а не создавали хаос, оставаясь при этом гибкими и масштабируемыми с ростом проекта.