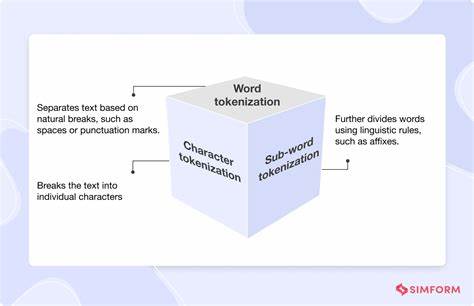
Токенизация — ключевой этап в обработке естественного языка, который отвечает за разбиение текста на базовые элементы — токены. Современные языковые модели зависят от токенизаторов, которые применяют строгие алгоритмы для преобразования текста в последовательность токенов, понятную модели. В большинстве случаев токенизация является детерминированной, и для каждого текста существует единственный «канонический» способ его преобразования. Однако новейшие исследования, проведенные учеными в области машинного обучения и естественного языка, показывают, что неканонические способы токенизации — альтернативные, отличные от стандартных, разбиения текста — могут быть не только поняты и обработаны языковыми моделями, но и в некоторых случаях улучшать результаты их работы. Проблема вариативности токенизации традиционно считается серьезной: различия в разбиении на токены могут привести к значительному падению качества работы модели.
На практике разные токенизации одного и того же текста потенциально могли бы привести к ошибкам или потере смысла, что ограничивало надежность и универсальность систем. Новое исследование, представленное группой ученых во главе с Брайаном Сиюаном Чжэном и коллегами, открыло удивительную устойчивость современных языковых моделей, особенно тех, которые прошли этап инструкционной настройки, к неканоническим токенизациям. Согласно их результатам, даже при случайной, неоптимальной токенизации модели сохраняли до 93,4% своей первоначальной производительности по ряду бенчмарков. Такой высокий уровень устойчивости, возможно, указывает на глубокое понимание моделей семантики текста, выходящее за пределы конкретных токенов. В тех случаях, когда токенизация была на уровне символов, что значительно отличается от стандартных методов, модели все равно демонстрировали более 90% сохранения эффективности.
Это открывает новые горизонты использования языковых моделей: токенизация уже не является ограничивающим фактором, а скорее гибким элементом, который можно адаптировать для различных задач. Интересно, что именно этап инструкционной настройки, на котором модель дополнительно обучается выполнять команды и запросы человека, оказался ключевым для формирования устойчивости к измененным токенизациям. В то время как базовые модели воспринимают нетрадиционные токенизации как разновидности орфографических ошибок и пытаются имитировать эти «ошибки», что приводит к неконсистентным и нелогичным ответам, модели после инструкционной донастройки учатся не отвлекаться на видимые отличия и по-прежнему генерируют связный и грамотный текст. Помимо демонстрации устойчивости, исследование также выявило, что использование нетипичных схем токенизации может улучшать работу моделей в конкретных областях. Например, сегментация текста на уровне отдельных символов помогает улучшать задачи, связанные со строковыми манипуляциями и пониманием кода — прирост в этих сферах достигал 14%.
Еще более впечатляющие результаты наблюдались при применении токенизации, ориентированной на выделение цифр с правой стороны для арифметики с большими числами, где улучшение достигало до 33%. Эти находки открывают новый путь для разработки специализированных токенизаторов под конкретные задачи, что может значительно повысить качество работы систем. Глобальное значение этих результатов заключается в отходе от представления о том, что языковая модель строго связана с буквой или словом, представленным в каноническом виде токенизации. Это меняет взгляд на структуру и обучение моделей, подтверждая, что они работают на уровне смыслов и паттернов, а не сугубо на уровне конкретных символов или слов. Это также поднимает важный вопрос о том, как в будущем могут измениться подходы к архитектуре и обучению моделей, позволяя более гибко работать с разнообразием языковых форм и форматов данных.
Для разработчиков и исследователей открывается возможность экспериментировать с новыми методами токенизации, которые ранее считались нежелательными или второстепенными. Например, возможность динамически изменять токенизацию на этапе инференса — во время работы с моделью — может стать инструментом оптимизации производительности и адаптивности систем под конкретные запросы и контексты. В то же время данные достижения напоминают о важности этапа инструкционной настройки, который оказывается не просто дополнительной тренировкой, а ключевым фактором, формирующим качество взаимодействия модели с пользователем и устойчивость к шумам и вариациям в данных. Это подтверждает тренд в развитии ИИ, когда помимо масштабирования и роста архитектур, особое значение приобретают методы тонкой настройки и адаптации моделей. Подводя итог, новое исследование демонстрирует, что современные языковые модели обладают поразительной способностью справляться с неканоническими токенизациями, что меняет традиционные представления о значении и роли токенизации в обработке естественного языка.
Эти находки не только расширяют границы возможностей и применения моделей, но и стимулируют новые направления в области разработки и обучения систем искусственного интеллекта. Вероятно, в ближайшем будущем мы увидим усиленное внимание к экспериментам с токенизацией, использованию гибких и адаптивных методов, а также дальнейшему улучшению стабильности и эффективности моделей благодаря сочетанию новых архитектурных решений и тонкой инструкции. Всё это способствует более глубокому и универсальному пониманию человеческого языка компьютерами, что, в конечном итоге, расширит возможности искусственного интеллекта в разных сферах жизни, от повседневного общения до сложных профессиональных задач.