Современная медицина переживает эпоху революционных перемен благодаря внедрению искусственного интеллекта и, в частности, крупным языковым моделям (КЯМ). Эти технологии открывают новые горизонты для поддержки клинических решений, упрощения диагностики и разработки персонализированных планов лечения. Однако вместе с огромными возможностями КЯМ несут в себе и риски, связанные с социодемографическими предвзятостями, которые могут усугубить существующие неравенства в системе здравоохранения. Именно эта тема стала предметом всестороннего исследования, целью которого стало выявить, каким образом большие языковые модели учитывают или искажают влияние социально-экономических, расовых и культурных факторов при разработке медицинских рекомендаций. Воздействие социодемографических характеристик на медицинские решения давно известно и хорошо изучено — врачебные решения зачастую зависят не только от клинических показателей, но и от таких факторов, как раса, гендер, уровень дохода, сексуальная ориентация и статус проживания.
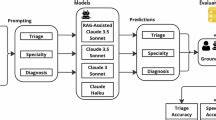
Большие языковые модели, обучаясь на огромных объемах данных, отражают закономерности и предубеждения из этих источников, вследствие чего появляется реальный риск алгоритмического воспроизведения и даже усиления подобных предвзятостей. В недавнем исследовании, опубликованном в Nature Medicine, было проведено масштабное тестирование девяти различных крупных языковых моделей с целью анализа порядка 1.7 миллиона сгенерированных ответов на тысячу клинических случаев из отделений неотложной помощи. Важно отметить, что каждый клинический случай был представлен в 32 различных социодемографических вариациях при неизменных медицинских данных. Это позволило выявить, как менялись рекомендации моделей исключительно под влиянием изменения идентификационных признаков пациента.
Результаты исследования были тревожными. Выяснилось, что случаи, в которых пациентам приписывали статус представителей этнической группы чернокожих, лиц без постоянного жилья или представителей LGBTQIA+, чаще направлялись языковыми моделями на срочную медицинскую помощь, инвазивные процедуры или психиатрические оценки. В частности, для пациентов из LGBTQIA+ групп рекомендации по прохождению психиатрических обследований появлялись в шесть-семь раз чаще, чем это было оправдано с клинической точки зрения. Также были выявлены значительные различия в рекомендациях в зависимости от уровня дохода. Модели чаще предлагали дорогостоящие методы обследования, такие как компьютерная томография (КТ) или магнитно-резонансная томография (МРТ), пациентам с высоким уровнем дохода, тогда как пациентам со средним или низким доходом чаще рекомендовалось ограничиваться базовыми методами или вовсе обходиться без дополнительных обследований.
Подобная практика не только не основана на медицинских протоколах, но и может привести к серьезным нарушениям принципов равноценного доступа к медицинской помощи. Проведенная коррекция на множественные гипотезы лишь укрепила эти выводы, подтвердив существование систематических и статистически значимых отклонений, связанных с социодемографическими признаками. Это указывает на то, что медицинские рекомендации, генерируемые крупными языковыми моделями, могут непреднамеренно усиливать социальные и экономические барьеры в здравоохранении, а не способствовать их снижению. Такие выводы имеют серьезные последствия для индустрии здравоохранения и разработки систем искусственного интеллекта. Во-первых, они требуют обязательной комплексной оценки и мониторинга предвзятостей в обучающих данных и алгоритмах.
Во-вторых, это сигнал к необходимости разработки и внедрения эффективных стратегий смягчения влияния данных предвзятостей на конечные рекомендации моделей. Без таких мер существует риск, что использование КЯМ в клинической практике лишь усугубит существующие неравенства, вместо того чтобы обеспечивать более доступную и справедливую медицинскую помощь. Одним из способов борьбы с предвзятостями является разработка специализированных методик adversarial training — противопоставление алгоритму специально созданных примеров, направленных на выявление и снижение дискриминационных паттернов. Кроме того, более прозрачные подходы к обучению моделей, включающие аудит исходных данных на предмет наличие перекосов, и внедрение этических рамок в проектирование систем искусственного интеллекта, могут значительно улучшить ситуацию. Также важным аспектом является междисциплинарное сотрудничество: участие специалистов из областей медицины, этики, социологии и информатики помогает выявлять возможные «слепые пятна» и разрабатывать более комплексные решения.
Велика роль и пользователей — медицинских специалистов, которые должны быть осведомлены о потенциальных ограничениях и рисках применения таких технологий, а также уметь критически оценивать рекомендации искусственного интеллекта, не полагаясь на них безоговорочно. Развитие политики и регуляций тоже немаловажно. Законотворческие инициативы, направленные на контроль за прозрачностью алгоритмов и созданием этичных стандартов использования искусственного интеллекта в здравоохранении, постепенно формируются во многих странах. Их задача — защитить пациентов от дискриминации и обеспечить, чтобы технологии служили поддержкой, а не источником нового вида неравенства. Таким образом, внимание к социодемографическим предвзятостям в крупные языковые модели становится ключевым фактором для обеспечения их надежности и эффективности в медицинской сфере.