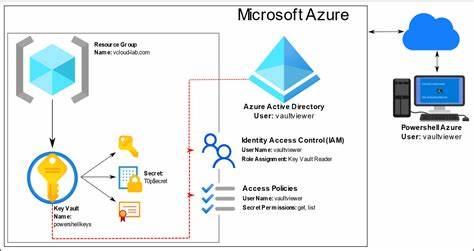
![Scaling ML compilers to trillion trillion FP operations [video]](/images/82E3DAE6-04A8-4491-A1A1-E35AF4BAC402)
С развитием машинного обучения и искусственного интеллекта требования к вычислительным мощностям стремительно возрастают. Современные модели и сети становятся всё более сложными, и для их эффективного обучения и оптимизации необходимы высокопроизводительные вычислительные решения. Одним из ключевых аспектов в этой области выступают машинные обучающие компиляторы (ML-компиляторы), способные преобразовывать и оптимизировать код под конкретное аппаратное обеспечение. Однако, чтобы обеспечить обработку невероятных объемов вычислений — вплоть до триллионов триллионов операций с плавающей запятой — требуется новая ступень в их масштабировании и оптимизации. В последние годы развитие ML-компиляторов движется в сторону повышения эффективности, параллелизации и адаптивности.
Традиционные подходы к компиляции кода машинного обучения стали недостаточно производительными для современных требований, где модели используют огромные массивы данных и вычислений с плавающей запятой, включая высокоточечные операции в формате FP32, FP16, bfloat16 и другие. Масштабирование таких компиляторов включает не только улучшение алгоритмов оптимизации, но и интеграцию с новейшими процессорными архитектурами, например графическими процессорами (GPU), тензорными процессорами (TPU), а также специализированными ускорителями искусственного интеллекта. Одной из главных сложностей при работе с экстремально большими объемами операций является необходимость эффективного управления памятью и синхронизации потоков вычислений. Без грамотной оптимизации многие параллельные вычисления могут столкнуться с узкими местами, приводящими к снижению производительности. Поэтому в современных ML-компиляторах реализуются продвинутые техники планирования задач, динамического распределения ресурсов и минимизации задержек между вычислительными блоками.
Помимо аппаратной составляющей, важно и программное обеспечение, поддерживающее гибкую автоматизацию лагерей параметров и автоматический подбор оптимальных графов вычислений. Это значительно упрощает задачу исследователям и инженерам машинного обучения, позволяя сосредоточиться на разработке модели без постоянного ручного вмешательства в методы оптимизации кода. Одним из перспективных направлений является использование автоматического машинного обучения (AutoML) для оптимизации самого компиляционного процесса, что открывает новые горизонты для повышения эффективности исполнения. Благодаря улучшению компиляторов и их масштабированию на триллионы триллионов операций с плавающей запятой появляется возможность решать задачи ранее недоступного уровня сложности. Например, глубокое обучение на огромных датасетах, моделирование сложных физических и биологических процессов, а также повышение точности прогнозных систем.
Видеоматериалы, посвящённые этой теме, часто раскрывают принципы работы масштабируемых ML-компиляторов и демонстрируют реальные примеры повышения производительности вычислений, что является важным ресурсом для специалистов в области ИИ и высокопроизводительных вычислений. В результате масштабирование ML-компиляторов — это не просто технический вызов, а стратегическое направление, содействующее развитию искусственного интеллекта на всех уровнях. Эффективное использование вычислительных мощностей и умение обрабатывать экстремально большие объемы операций с плавающей запятой открывают двери для новых научных открытий и коммерческих приложений, ранее считавшихся невозможными. Будущее машинного обучения напрямую связано с совершенствованием способов компиляции и оптимизации моделей, а также с интеграцией этих методов в современные вычислительные платформы, способные масштабироваться до триллионов триллионов операций, что значительно расширит возможности анализа данных и создания интеллектуальных систем нового поколения.