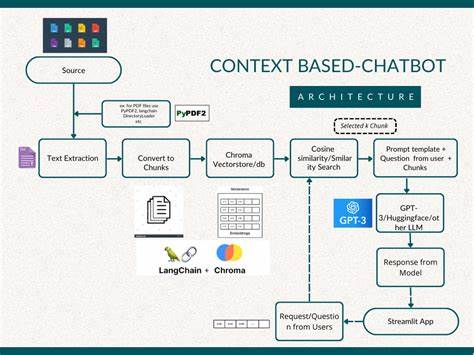
В современном цифровом мире искусственный интеллект стал неотъемлемой частью поддержки пользователей и взаимодействия с техническими продуктами. Одним из ключевых элементов эффективной работы таких систем являются подробные и структурированные технические документы. Большие языковые модели (LLM), современные ИИ-агенты и чатботы значительно облегчают процесс поиска ответов и решений для пользователей, но их эффективность напрямую зависит от качества исходной документации, на которую они опираются. При неправильном подходе к подготовке и оформлению технического контента результат может быть неудовлетворительным, создавая у пользователей чувство фрустрации из-за отсутствия ответов или некорректной информации. Оптимизация документации для взаимодействия с LLM и другими искусственными интеллектуальными помощниками требует внимания к деталям и создания особого подхода, сочетающего ясность изложения для человека и структурированность для машин.
Основная задача состоит в построении информационной среды, где каждый фрагмент данных легко распознаётся моделью ИИ и может быть эффективно использован для генерации точных, полезных и понятных ответов. Одним из главных принципов является обеспечение полноты информации. Искусственный интеллект не способен изобретать или создавать данные, отсутствующие в исходной документации. Часто базовые пользовательские сценарии, такие как отмена подписки, удаление аккаунта или смена пароля, упускаются из виду, считаясь «очевидными» задачами, однако их отсутствие приводит к недостаточной поддержке пользователей через ИИ-ассистентов. Это создаёт баги в работе чатботов, когда они либо признаются в невозможности предоставить ответ, либо пытаются дать общий, и зачастую неправильный, совет.
Для предотвращения подобных ситуаций важно тщательно проработать документацию именно с позиции основных пользовательских действий, а также учесть уникальные функции продукта — будь то конфигурация вебхуков, ротация API-ключей или интеграция с другими сервисами. Кроме того, важным фактором является то, что каждая страница документации должна быть полноценной и самостоятельно содержательной. Множество современных ИИ-агентов обрабатывают информацию по частям, и поэтому логика последовательного перехода между разделами, понятная обычному читателю, может не восприниматься машиной. Если страница включает ссылки на знания, изложенные ранее, без краткого контекста, ИИ-ассистенты рискуют предоставить неполный или запутанный ответ. В связи с этим всем разделам следует иметь чёткое введение с описанием предмета и ссылками на связанные темы, чтобы информация воспринималась как завершённый сегмент, доступный для обработки отдельно от остального документа.
Структура содержимого играет критически важную роль. Разделы с множественной направленностью, которые одновременно покрывают разные темы, затрудняют работу языковых моделей, приводя к смешению контекста и снижение точности ответов. Оптимальным является разделение контента таким образом, чтобы одна секция отвечала лишь на один конкретный вопрос или решала одну задачу. Такой подход способствует лучшему пониманию структуры документации как человеком, так и ИИ, улучшает навигацию и повышает эффективность поиска. Не менее существенной рекомендацией является регулярная проверка и очистка документации от устаревших, дублированных или нерелевантных материалов.
Избыточные и разрозненные данные становятся источником «шума» для анализа языковыми моделями, усложняют выделение точных ответов и приводят к появлению конфликтующих сведений. Концентрируясь на актуальном и важном содержании, качество взаимодействия с ИИ значительно улучшается, поддерживая единую и логичную работу всей системы. Для повышения качества и актуальности контента крайне полезным является анализ обратной связи от пользователей и их вопросов, поступающих через ИИ-ассистентов и службы поддержки. Повторяющиеся запросы выявляют пробелы в документации, неочевидные области или недостаток практических примеров. Такие данные помогают приоритизировать доработки и повысить удобство как человеческого пользователя, так и ИИ-модели, способствуя непрерывному развитию документального набора.
Исключительную значимость в технической документации имеют полнота и контекстность кодовых примеров. Частичные или фрагментарные сниппеты, лишённые связности и необходимых импортов, снижают способность ИИ точно интерпретировать и рекомендовать решения. Полные примеры с ясным описанием структуры файлов и окружения способствуют генерации максимально корректных и конкретных подсказок для разработчиков и пользователей. Ещё одна важная составляющая — поддержание единообразной терминологии с помощью создаваемого глоссария. Разночтения и неоднозначные определения снижают связность и качество результатов обработки запросов.
Последовательное использование терминов и предварительное раскрытие аббревиатур создаёт однозначную информационную среду, помогающую ИИ-чатикам правильно связывать понятия и обеспечивать полноту ответов. Описание визуальных и интерактивных элементов — серьёзный аспект, так как многие ИИ-системы пока не способны воспринимать графический контент или взаимодействовать с интерфейсом продукции. Наличие текстовых описаний для скриншотов, кнопок и пошаговых действий позволяет ИИ предоставлять исчерпывающие рекомендации вместо того чтобы оставлять пользователя без поддержки в визуальных вопросах. Для стабильной работы ИИ-ассистентов следует уделить внимание технической реализации документации. Контент должен быть доступен в статическом HTML, поскольку динамически подгружаемый с помощью JavaScript материал зачастую остаётся вне зоны видимости AI-краулеров.
Использование генераторов статических сайтов и тестирование документации с отключённым JavaScript обеспечивают, что база знаний будет корректно индексироваться и доступна для анализа. Также не стоит забывать о наполнении страниц метаданными, которые обеспечивают дополнительный контекст для понимания ассистентом специфики документа, темы, уровня сложности и взаимосвязей с другими материалами. Правильные заголовки, описания и категории помогают языковым моделям быстрее выбрать релевантный контент и обеспечить полноту периодически запрашиваемых знаний. Для проектов с большим количеством продуктов и разных аудиторий разумным решением является использование отдельных чатботов и моделей для каждого продукта. Это помогает избежать смешения понятий и повысить релевантность ответов, учитывая уникальный контекст и терминологию каждого направления.
Такой подход позволяет создать специализированные промпты и настроить взаимодействие с учетом целевых потребностей. Наконец, важный момент — помнить о человеческом факторе. Искусственный интеллект — это полезный инструмент, но не замена продуманного и качественного контента. Основные принципы создания документации — ясность, контекст и качество — остаются ключевыми, поскольку они выгодны как пользователям, так и ИИ-системам. Стремление удовлетворить реальные запросы и потребности людей одновременно улучшает работу чатботов и повышает лояльность аудитории.
Оптимизация технической документации для работы с LLM, ИИ-ассистентами и чатботами — это инвестиция, которая окупается за счёт ускорения адаптации новых пользователей, снижения нагрузки на службы поддержки и создания более эффективного пользовательского опыта. Внедрение описанных стратегий требует постепенного подхода, начиная с наиболее приоритетных изменений и последующей оценки их влияния на производительность ИИ-систем. Такой поэтапный процесс обеспечивает постоянное улучшение как самой документации, так и качества работы искусственного интеллекта, расширяя границы взаимодействия между человеком и машиной.