В современном мире технологии стремительно развиваются, а потребности пользователей — растут. Появление высокоинтерактивных и отзывчивых приложений требует создания сервисов, способных обрабатывать огромные объемы данных с минимальной задержкой. Одним из таких вызовов стала задача создания сервиса реального времени, способного принимать и обрабатывать 20 000 обновлений в секунду. В данной статье мы раскроем этапы создания подобного сервиса, расскажем о технических решениях и опыте, который поможет компаниям и разработчикам понять основные принципы построения масштабируемых систем с реальным временем. Изначальная идея и проблемы При создании сервиса реального времени одной из главных задач было предоставить пользователям возможность наблюдать за ходом выполнения фоновых задач.
Современные приложения, особенно связанные с искусственным интеллектом, обработкой видео, автоматизацией и мощными вычислениями, зачастую занимаются выполнением многозадачных процессов в фоне. Однако без своевременных обновлений UI пользователи сталкивались с ощущением "подвешенности" — они не понимали, идет ли работа, есть ли прогресс, возникли ли ошибки. Ярким примером стала обработка больших CSV-файлов. Пользователь загружает файл с тысячами строк, а система распараллеливает обработку каждой записи на отдельные фоновые задачи. Без системы обновлений реального времени интерфейс превращается в бессмысленную анимацию загрузки, что ухудшает пользовательский опыт и снижает доверие к продукту.
Прежде всего нам нужно было не просто обрабатывать запросы в фоне, но и информировать пользователя о состоянии этих процессов в реальном времени, отображая динамические индикаторы, статусные сообщения и метаданные. Однако реализация стала сложнее, чем казалась на первый взгляд. Технический путь к решению Планируя архитектуру, команда изначально предполагала задействовать WebSocket-соединения. WebSocket широко применяется во многих real-time проектах, позволяя поддерживать постоянное соединение между клиентом и сервером. Тем не менее, при масштабировании системы до десятков тысяч обновлений в секунду этот подход продемонстрировал ряд недостатков.
Первая сложность касалась поддержки исторических подписок. Пользователь может подключиться к сервису и захотеть получить обновления не только текущих процессов, но и тех, что стартовали ранее. WebSocket не предоставляет простого или естественного механизма для получения данных, созданных до открытия соединения. Кроме того, нагрузка на базу данных при использовании WebSocket возрастала экспоненциально. Каждое новое соединение требовало отдельного запроса к базе для получения первичных данных, а затем — постоянного поддержания соединения, что приводило к увеличению потребления ресурсов.
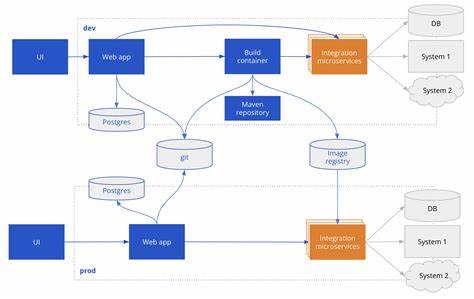
Разработкой отдельного уровня уведомлений приходилось заниматься директивно: используемые триггеры, очереди сообщений либо периодический опрос никак не обеспечивали желаемую производительность и надежность при высокой частоте обновлений. Выбор Postgres replication slots и ElectricSQL В ходе исследований и экспериментов была найдена альтернатива — использование слотов репликации Postgres в сочетании с ElectricSQL. Такой подход кардинально изменил архитектуру сервиса и позволил достичь поставленных целей. Postgres — это надежная и проверенная база данных с высоким уровнем масштабируемости и эффективного управления транзакциями. Использование слотов репликации позволяет получить упорядоченный и безопасный поток изменений, которые происходят в базе, непосредственно из журнала Write-Ahead Log (WAL).
Смысл решения заключался в том, чтобы трансформировать саму базу данных в источник правды не только для сохраненных данных, но и для их изменений в режиме реального времени. Через ElectricSQL клиентские запросы могут «подписываться» на определенные данные, получать сначала начальный результат, а затем — только измененные строки, используя транзакционный идентификатор как курсор. Таким образом мы решили сразу несколько задач: полную согласованность данных с базой, возможность подписываться на исторические данные, минимизацию нагрузки на базу, и избавились от необходимости строить отдельную систему уведомлений. Процесс взаимодействия с сервисом Когда задача или фоновая операция обновляет данные, например, вызывает команду metadata.set("key", "value"), происходят следующие этапы.
Обновление записывается в таблицу runs в Postgres. База заносит изменения в WAL. Replication slot отслеживает позиции в логе и передает новые данные ElectricSQL. На стороне пользователя после авторизации в системе браузер с помощью React-хуков инициирует подписку на определенный run или группу данных. Запрос направляется на слой ElectricSQL, который возвращает текущие результаты и стартовый транзакционный идентификатор.
После этого запросы переходят в режим живого ожидания (long-polling), обеспечивая мгновенную передачу обновлений. Применение JWT и авторизация Еще одним важным решением стало использование подписанных JSON Web Token (JWT) для авторизации подписчиков. Вместо постоянных запросов к базе для проверки прав доступа, система валидирует токены с учетом заранее заданных прав на создание, чтение и подписку. Это дало существенное преимущество по производительности, так как все проверки производились локально, а при этом сохранялась строгая система разграничения и безопасности доступа к данным. Механизмы ограничения нагрузки Не менее значимой составляющей стала реализация ограничения количества одновременных подключений и подписок.
В зависимости от тарифного плана пользователей (например, 500 одновременных подписок на Pro-план) система отслеживает количество активных соединений с помощью дерективных Redis Lua-скриптов. Данный подход позволяет эффективно реализовать скользящее окно подсчета, избегая конкурентных условий и обеспечивая стабильную работу даже при резком всплеске пользователей. Решение сложных задач фильтрации и кеширования данных Проблемы возникли также при реализации подписок по временным и пользовательским фильтрам: например, подписываться на все задачи, созданные за последний час, либо с определенным тегом. ElectricSQL требует фиксированных условий WHERE для корректной работы, поэтому постоянное изменение параметров фильтров вызвало бы создание чрезмерного числа Shape — технических сущностей для отслеживания подписок в базе. Для решения этой задачи был создан механизм кеширования фильтров, который позволил командам кэшировать состояние фильтров с высоким сроком жизни и предотвращать неконтролируемый рост подписок.
Кеш реализован с использованием комбинации памяти серверов и Redis, что позволило работать при большом масштабе и с высокой доступностью. Результаты и показатели производительности После продолжительной оптимизации и итеративного улучшения архитектуры удалось достичь впечатляющих результатов. Система уверенно обрабатывает до 20 000 обновлений в секунду на пике нагрузки, при этом ежедневно обрабатывается более 500 Гб данных, поступающих из Postgres. Задержка доставки обновлений пользователям сокращена до менее 100 миллисекунд, благодаря чему интерфейсы чувствуют себя мгновенно отзывчивыми, а пользователи получают полный доступ к динамическим состояниям фоновых процессов. Преимущества подхода с использованием Postgres и ElectricSQL Выбор архитектуры, базирующейся на Postgres replication slots и ElectricSQL, оказался очень удачным.
Во-первых, сохраняется единый источник правды, что упрощает процессы отладки и исключает рассогласования данных. Во-вторых, минимизируется нагрузка на базу, ведь не нужны отдельные каналы для уведомлений или постоянных запросов. Наконец, мы получили возможность строить подписки как на новые, так и на уже существующие и исторические данные, что значительно расширяет сценарии использования и повышает удобство для конечных пользователей. Заключение Создание высокопроизводительного сервиса реального времени — это всегда вызов, сочетающий в себе множество аспектов: от выбора архитектуры и технологий до решения вопросов безопасности и управления нагрузкой. Наш опыт показал, насколько важно использовать инновационные подходы, не бояться менять устоявшиеся практики и выбирать инструменты, максимально соответствующие целям.
Использование слотов репликации Postgres и ElectricSQL позволило нам построить сервис, который не просто обрабатывает огромные объемы данных, но делает это эффективно, надежно и масштабируемо. Такой подход можно рекомендовать компаниям, стремящимся построить собственные решения реального времени, где производительность, стабильность и удобство для пользователя являются приоритетами. Для разработчиков, желающих попробовать Trigger.dev Realtime, доступны подробные документация и удобные React-хуки, которые помогут быстро внедрить функциональность с минимальными усилиями. Инвестиции в качественное решение реального времени окупаются повышенной вовлеченностью пользователей и ростом доверия к продукту.
В эпоху больших данных и мгновенных изменений именно такие технологии задают тон будущему взаимодействия с цифровыми сервисами.