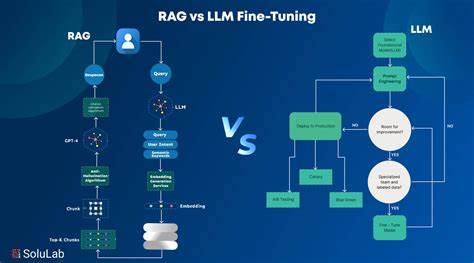
В эпоху цифровых технологий объемы технической документации растут с небывалой скоростью, и поддерживать их в актуальном состоянии становится все сложнее. Традиционный подход внедрения больших языковых моделей (LLM) для работы с документами предусматривал дообучение моделей на основе конкретных текстовых данных. Однако этот процесс требует значительных вычислительных ресурсов, времени и финансовых затрат. Более того, он часто не гарантирует ожидаемую точность и релевантность ответов. В ответ на эти сложности все большую популярность приобретает метод Retrieval-Augmented Generation (RAG) - подход, в котором поиск релевантных фрагментов документации сочетается с генерацией ответа на их основании.
Такой подход не требует дообучения модели, а значит, существенно упрощает внедрение и обеспечивает высокое качество взаимодействия с пользователем. RAG становится ключевым инструментом для превращения статичных, сложно читаемых и плохо индексируемых документов в интерактивного помощника. В основе концепции лежит идея о том, что использование специального поиска по заранее разбитым на смысловые части документам и генерации на их основе ответов позволяет преодолеть ограничения больших языковых моделей. Одной из главных проблем LLM считается ограниченный контекст, который они могут обработать одновременно. Передача модели всей документации целиком невозможна, а дообучение на ней создает дополнительную нагрузку и расходы.
Вместо этого RAG разбивает документы на небольшие фрагменты, называемые чанками, и генерирует для каждого векторное представление (эмбеддинг). При поступлении запроса система находит наиболее релевантные чанки благодаря поиску в векторном пространстве и передает их в качестве контекста модели, которая затем генерирует ответ на основе достоверной и проверенной информации. Главное преимущество RAG в работе с документацией - высокая точность и релевантность ответов, а также низкий уровень ошибок, связанных с вымыслом. Большие языковые модели склонны к генерации уверенных, но неверных ответов - так называемым галлюцинациям. Благодаря наличию документированных подтверждений в виде релевантных фрагментов, возвращаемых поисковым механизмом, модель ограничена в своих предположениях и выдает только проверенную информацию.
Это значительно увеличивает доверие пользователей к системе и снижает необходимость ручной проверки ответов. Кроме того, RAG существенно упрощает сопровождение и обновление системы. По мере изменения или добавления новой информации в документацию достаточно обновить поисковый индекс в векторном пространстве, пересоздав эмбеддинги для новых или измененных фрагментов. Модель же остаётся неизменной, что экономит ресурсы и минимизирует время внедрения изменений. Это особенно важно для крупных проектов с часто обновляющейся документацией, где постоянное дообучение или переобучение LLM было бы непрактично и дорого.
Экономическая эффективность RAG также впечатляет. Затраты на вычисления при создании эмбеддингов для большого количества документов, как правило, невысоки и совершаются однократно. Поиск релевантных элементов в индексе с помощью методов, таких как косинусное сходство, отличается высокой скоростью и низкой стоимостью. Последующая генерация ответов с помощью предобученных моделей, таких как GPT-4 или других более лёгких версий, происходит с минимальными задержками и по значительно меньшей цене, чем при необходимости многократного дообучения. Помимо технических и экономических аспектов, RAG выполняет важную роль в обратной связи с пользователями и развитии продукта.
Система логирует все пользовательские запросы, что даёт возможность анализировать, какие темы вызывают затруднения, какие вопросы задают чаще всего, а также выявлять новые запросы и пожелания. Такая аналитика помогает команде разработчиков и продуктовым менеджерам выявлять пробелы в документации, планировать улучшения и расширение функционала. Фактически система становится не просто ботом поддержки, а полноценным каналом для сбора инсайтов и формирования стратегии развития. Применение RAG не ограничивается только технической документацией. Этот подход можно легко масштабировать и для других источников информации: базы знаний, статьи в блогах, тикет-системы и даже базы данных.
Объединение разных источников позволит создать единый интеллектуальный помощник, который способен предоставить всесторонние и структурированные ответы на любые вопросы, связанные с продуктом или услугой. Разработка RAG-системы обычно начинается с обработки и подготовки документов. Автоматический сканер находит все исходные файлы, например, в формате Markdown, и загружает их для последующей обработки. Текст разбивается на смысловые блоки, учитывая контекст и перекрытия между соседними чанками для сохранения целостности информации. Для каждого блока создаётся векторное представление с помощью API OpenAI или другого специального инструмента для эмбеддингов.
Для хранения и быстрого поиска по векторным представлениям используются специализированные векторные базы данных, такие как Chroma, Pinecone или Qdrant. Когда пользователь задаёт вопрос, он конвертируется в эмбеддинг и сравнивается с векторным индексом документа для выявления наиболее релевантных элементов. Затем выбранные фрагменты добавляются в системный запрос к LLM, который формирует развернутый ответ, основанный на фактических данных из документации. Часто ответ выводится в режиме потоковой передачи, что повышает скорость и удобство взаимодействия. Пользовательский интерфейс такой системы обычно сочетает классический поиск с чат-ботом, где можно вести диалог на естественном языке.
Он адаптируется под разные платформы и сделан максимально наглядным и удобным с помощью современных UI-фреймворков и инструментов стилизации, таких как Tailwind CSS. Такая универсальность облегчает интеграцию и адаптацию системы под нужды конкретного проекта. Текущие ограничения метода связаны с настройкой параметров - оптимального размера чанков, степени перекрытия, количества возвращаемых фрагментов и параметров поиска. Эти показатели подбираются эмпирически и требуют тестирования для достижения баланса между полнотой контекста и производительностью. Также нужно продумывать автоматический механизм обновления эмбеддингов при изменении документации, чтобы поддерживать актуальность информации без излишнего дублирования.
В заключение стоит отметить, что RAG представляет собой революционный подход в работе с документами и большими языковыми моделями. Вместо того чтобы тратить ресурсы на масштабное дообучение моделей, достаточно объединить качественный поиск по документации с генерацией осмысленных ответов. Такой подход не только улучшает качество поддержки и снижает издержки, но и превращает документацию в активный инструмент для улучшения продукта и повышения лояльности пользователей. Современные компании, стремящиеся к эффективной и современной коммуникации, всё чаще выбирают RAG как основной механизм взаимодействия с техническими знаниями. .







