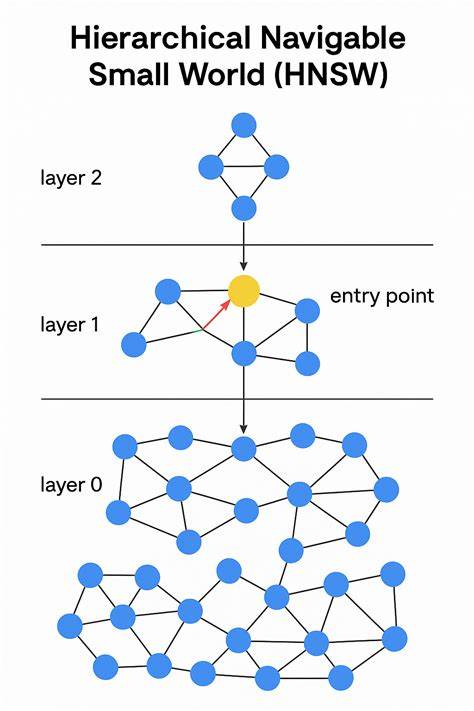
Современный мир данных стремительно развивается, формируя огромные массивы информации, которые требуют качественных и быстрых методов обработки и поиска. Проблема быстрого поиска по большому количеству высокоразмерных данных становится все более актуальной. На этом фоне технологии ближайших соседей и алгоритмы, способные эффективно работать с многовекторными данными, приобретают особое значение. Одним из перспективных решений в этой сфере является Multi-Vector HNSW, реализованный на чистом Java. Этот проект представляет собой библиотеку, которая воплощает в себе алгоритм HNSW (Hierarchical Navigable Small World) с возможностью работы с не одним, а сразу несколькими векторами.
Именно поддержка многовекторных данных выгодно выделяет Multi-Vector HNSW на фоне классических инструментов. На практике это означает возможность осуществлять поиск и сравнительный анализ сложных наборов данных, которые описываются несколькими векторами одновременно — в результате качество поиска заметно повышается, а вычислительные операции оптимизируются. В основе проекта лежит Java 17 – современная версия языка программирования, которая обеспечивает повышенную производительность и доступ к инновационным технологиям. Особенно стоит выделить использование Java Vector API, предназначенного для выполнения высокопроизводительных векторных вычислений. Это позволяет значительно ускорить операции по подсчету расстояний между объектами, что является ключевым этапом алгоритма HNSW.
Алгоритм HNSW относится к семействам алгоритмов поиска по ближайшим соседям в высокоразмерном пространстве. Его главная задача – найти объекты, максимально близкие к заданному запросу по определенной метрике, как правило, евклидовой или косинусной. Разработанный с фокусом на иерархичность и удобство навигации, HNSW обеспечивает быструю и точную навигацию по графу, что существенно сокращает время отклика системы. Поддержка нескольких векторов одновременно открывает новые горизонты для анализа. Его можно внедрять в области, где объекты описываются комбинированным набором признаков, таких как мультимодальные данные, объединяющие текстовые, визуальные и звуковые компоненты.
Многовекторный подход обеспечивает более глубокое понимание и поиск, поскольку создается комплексная модель сходства, учитывающая разные аспекты данных и их взаимные взаимосвязи. Для разработчиков и инженеров, работающих над системами рекомендательных алгоритмов, интеллектуального поиска и обработки естественного языка, Multi-Vector HNSW представляет собой мощный инструмент. Он позволяет реализовывать высокоэффективные решения без необходимости перехода на другие языки или фреймворки. Библиотека написана на чистом Java, что гарантирует совместимость с большинством существующих проектов и легкость интеграции. Для управления большими объемами данных фундаментально важна оптимизация производительности, снижение задержек и использование современных средств параллельных вычислений.
Использование возможностей Java Vector API позволяет добиться значительного увеличения скорости векторных операций за счет SIMD (Single Instruction, Multiple Data). Этот подход позволяет одновременно обрабатывать множество элементов данных, что существенно сокращает время обработки и повышает пропускную способность систем. Open-source характер проекта делает его особенно привлекательным для исследователей и разработчиков. Все желающие могут получить исходный код, ознакомиться с архитектурой, внести свои предложения и улучшения. Это способствует активному развитию экосистемы, продвижению инноваций и внедрению актуальных наработок в индустриальные решения.
Области применения Multi-Vector HNSW весьма разнообразны. В сфере машинного обучения и искусственного интеллекта алгоритм можно использовать для построения эффективных систем классификации, кластеризации и анализа схожести сложных объектов. В индустрии информационного поиска — для создания интеллектуальных поисковых систем, способных работать с мультимедийными и комплексными данными, улучшая точность результата и пользовательский опыт. Технологические тренды, направленные на развитие обработки многомерных данных, делают Multi-Vector HNSW одним из важных инструментов будущего. Применение адаптивных методов, построенных на основе графовых структур и векторных данных, позволяет не только ускорить поиск и обработку, но и повысить качество принятия решений в разнообразных прикладных областях.
Помимо технической составляющей, проект демонстрирует, что Java не утрачивает своей актуальности и может конкурировать с языками, традиционно считающимися более производительными в сфере машинного обучения и обработки больших данных. Использование современных возможностей, таких как Vector API в Java 17, меняет представления о том, каким должен быть высокопроизводительный код в экосистеме Java. Для начинающих специалистов в области обработки данных и разработчиков, стремящихся внедрять передовые алгоритмы в свои проекты, Multi-Vector HNSW предоставляет не только инструмент, но и ценный образовательный материал. Изучение архитектуры и принципов работы библиотеки позволяет глубже понять внутренние механизмы поиска близких соседей и сложности, связанные с высокоразмерными данными. Таким образом, библиотека Multi-Vector HNSW является мощным современным решением, сочетающим простоту внедрения, высокую производительность и расширенные возможности обработки сложных многовекторных данных.
Ее открытость, использование новых стандартов Java и фокус на практичной реализации делают проект востребованным инструментом для широкого круга профессионалов в области обработки данных и разработки интеллектуальных систем.