Современный мир стремительно движется в сторону интеллектуальных систем, способных обрабатывать и интерпретировать огромные объемы данных, находящихся в свободном и структурированном виде. Семантический веб выступает в роли одного из ключевых элементов этой революции, буквально преобразуя интернет из хранилища документов в глобальную базу знаний. Важным инструментом для работы с семантическими данными становится Prolog — язык программирования, который благодаря богатой логической природе идеально подходит для задач вывода и обработки знаний. Его интеграция с семантическим вебом обещает существенно расширить возможности автоматизации интеллектуального анализа и принятия решений в различных сферах деятельности. Семантический веб — концепция, введенная в начале XXI века, предполагает описание информации таким образом, чтобы компьютеры могли понимать смысл данных, а не просто их отображать.
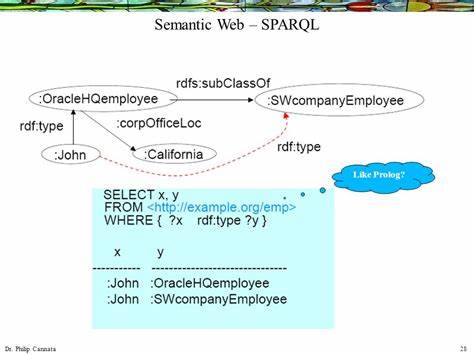
Это достигается с помощью формальных описательных языков, таких как RDF, OWL, и SPARQL, которые позволяют создавать сложные модели знаний, способные взаимодействовать и объединяться в единую сеть. Однако для эффективно использования этих возможностей необходим интерфейс, ориентированный на логическое программирование и автоматический вывод. Prolog, будучи языком с внутренней логикой, обладает всеми преимуществами для реализации такого интерфейса. Одной из основных причин популярности Prolog в обработке семантической информации является его декларативный характер. Вместо явного указания шагов решения задач в Prolog описываются правила и факты, из которых система самостоятельно строит выводы.
Такая методика особенно удобна для работы с онтологиями — формальными описаниями предметных областей, которые лежат в основе семантического веба. Семантический веб-интерфейс для Prolog представляет собой мост между формальными моделями знаний и бизнес-приложениями, научными исследованиями или системами поддержки принятия решений. Он обеспечивает удобную среду для загрузки, анализа и манипулирования семантическими данными, предлагая простые и мощные средства для автоматических выводов и интерпретации информации. Важным элементом этого интерфейса становится возможность работы с форматами данных семантического веба напрямую внутри Prolog. Проекты, такие как семантический парсер Turtle или локальные реализации SPARQL-движков, интегрируются с движком Prolog, позволяя загружать RDF-графы, выполнять запросы и на основании логических правил формировать новые знания.
Это расширяет традиционные рамки Prolog и открывает новые возможности для интеллектуального анализа информации. Одной из заметных проблем в области настройки семантического веб-интерфейса для Prolog выступает сложность обработки больших объемов данных, реализуемых в виде онтологий и графов. Однако разработчики применяют эффективные алгоритмы индексирования и кэширования, а также используют функционал многослойного анализа, что существенно повышает производительность и масштабируемость решения. Кроме того, открытые проекты с поддержкой семантического веба и Prolog активно развиваются сообществом, формируя обширный экосистемный набор инструментов. Это значительно облегчает интеграцию в уже существующие информационные системы и позволяет оперативно адаптировать технологии под разнообразные задачи.
Семантический веб-интерфейс на базе Prolog находит применение в научных исследованиях, например, в области биоинформатики и цифровой гуманитаристики, где требуется работать с базами взаимосвязанных данных, а также формализованными знаниями. Автоматизация вывода и возможность описательной логики делают Prolog незаменимым помощником для ученых и специалистов, стремящихся раскрыть скрытые взаимосвязи между объектами и явлениями. Такое программное решение также востребовано в промышленности и бизнесе для построения интеллектуальных систем поддержки принятия решений. Логическое программирование позволяет создавать гибкие модели с учетом многочисленных правил, исключений и доменных ограничений, что улучшает точность и адаптивность аналитических систем. Внедрение семантического веб-интерфейса для Prolog способствует совершенствованию систем автоматического контроля качества, управления знаниями и классификации информации, что особенно актуально в условиях взрывного роста данных и усложнения информационных структур.