В современном мире, насыщенном данными, задача эффективной обработки информации становится все более актуальной. Одним из передовых подходов к решению этой проблемы является распределенный информационный бутылок, или Distributed Information Bottleneck (DIB). Этот метод предлагает новый взгляд на структурирование данных и выявление наиболее значимых признаков для предсказательных моделей. Рассмотрим подробнее, что такое DIB и как он может изменить подход к обработке информации. Распределенный информационный бутылок — это концепция, которая основывается на минимизации избыточной информации, сохраняя при этом ключевые характеристики данных.
В традиционных моделях машинного обучения основной целью является максимизация точности предсказаний с использованием сложных алгоритмов. Однако, такой подход часто приводит к переобучению модели и затрудняет интерпретацию результатов. DIB, с другой стороны, фокусируется на том, чтобы выяснить, какая информация является по-настоящему важной для выполнения задачи, и тем самым устраняет излишества. Что делает DIB уникальным, так это его способность рассматривать каждый признак данных отдельно. Например, если мы анализируем медицинские записи, то можем выделить такие признаки, как возраст пациента, уровень сахара в крови или температура.
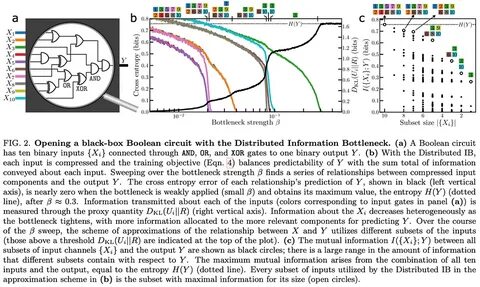
DIB позволяет установить, какой из этих факторов наиболее важен для предсказания вероятного диагноза. Это достигнуто путем оценки информации, содержащейся в каждом из признаков, и их взаимодействий, что позволяет достигать лучших результатов при гораздо меньшем количестве данных. Ключевым компонентом DIB является использование вариационного автокодировщика (VAE), который помогает эффективно упаковывать информацию в форму, удобную для дальнейшего анализа. Распределенный информационный бутылок работает как вероятностный кодировщик для каждого признака, а также включает в себя штраф за отклонение (KL-разность), который увеличивается по мере обучения модели. Это создает условия, при которых модель фокусируется на наиболее значительной информации, отсекая все остальное.
Для удобства использования, функциональность DIB интегрирована в класс TensorFlow Keras, называемый DistributedIBNet. Этот инструмент позволяет исследователям и разработчикам легко запускать и настраивать модели с помощью стандартных методов Keras. В частности, DIB предоставляет возможность настраивать скорость "аннейлинга" — процесс постепенного уменьшения штрафа за исключение информации по мере обучения модели. Благодаря этому подходу, пользователи получают доступ к механизмам, которые позволяют контролировать, как именно информация представляется в процессе обработки. Одним из значимых аспектов DIB является возможность визуализировать потоки информации.
На основе данных, собранных в процессе обучения, пользователи могут создавать графики, которые показывают, как именно изменяется распределение информации по признакам по мере обучения модели. Это может помочь не только в исследовательской деятельности, но и в практическом применении, например, в медицине, где понимание ключевых факторов может привести к более точным диагнозам и эффективным методам лечения. Использование DIB не ограничивается лишь табличными данными. Методы DIB можно применять и к более сложным типам данных, таким как временные ряды или изображения. В таких случаях может потребоваться предварительная обработка данных с использованием специализированных нейронных сетей для извлечения значимой информации.
DIB гарантирует, что в конечном итоге вся информация будет сгруппирована и представлена в едином пространстве, что упрощает анализ и интерпретацию. Однако, как и любой другой метод, DIB имеет свои ограничения и требует глубокого понимания основ машинного обучения. Для успешного применения DIB важно осознавать, какие именно признаки могут быть предпочтительными для выбора и какие значения имеют в разных контекстах. Это требует от специалистов не только технических навыков, но и оценки данных, что может быть сложным для неопытных пользователей. Тем не менее, DIB представляет собой мощный инструмент для исследователей и практиков, стремящихся оптимизировать процесс анализа данных.