Графические процессоры AMD RDNA 4 демонстрируют впечатляющие достижения в области вычислительной производительности, значительно улучшая возможности для ускорения операций с матрицами благодаря интеграции матричных ядер третьего поколения. Эти аппаратные новшества открывают перед разработчиками широкие возможности по оптимизации Generalized Matrix Multiplication (GEMM) — базовой операции для машинного обучения, научных расчетов и компьютерной графики. Особое внимание уделяется новому подходу к работе с внутренними регистрами и использованию специализированных инструкций Wave Matrix Multiply Accumulate (WMMA), которые обеспечивают эффективное разделение нагрузки между вычислительными потоками и снижают нагрузку на регистры VGPR (Vector General Purpose Registers). В сравнении с предыдущим поколением RDNA 3 архитектура RDNA 4 предлагает удвоенную производительность по FP16 с 512 FLOPS на такт на вычислительный блок до 1024 FLOPS, а также поддержку полуточных bf16 операций и удвоенную пропускную способность для операций с 8-битными целыми значениями. Это серьезный шаг вперед, который реализован не только на аппаратном уровне, но и в наборе новых встроенных функций и инструкций, значительно упрощающих программирование и максимизирующих выгоду от аппаратных улучшений.
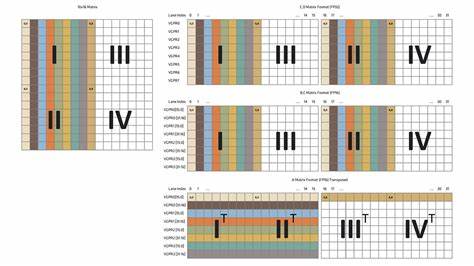
Главная особенность использования матричных ядер RDNA 4 — это изменение формата распределения данных в VGPR, что привело к устранению необходимости в дублировании элементов матриц и сложных межпотоковых обменах, присущих RDNA 3. В RDNA 4 каждая нить в волновом фронте загружает небольшую часть матрицы — восемь элементов — что при 32 нитях полностью покрывает размер 16 на 16 без избыточного копирования. Этот подход снижает расход регистров и обеспечивает более эффективное использование вычислительных ресурсов. Использование новых WMMA интринсиков связано с вызовом инструкций, ориентированных на весь волновой фронт, а не на отдельные нити. Особое внимание уделяется функции __builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12, которая берет матрицы A и B в формате 16-битных чисел с плавающей запятой и вычисляет произведение с накоплением результата в 32-битном формате.
Такая организация позволяет сохранять точность итогового результата, одновременно ускоряя вычисления за счет использования преимуществ полуточной арифметики. Программирование с использованием WMMA-интринсиков требует понимания распределения данных и владения приемами загрузки и выгрузки данных в VGPR. Важным моментом является возможность упаковки двух 32-битных чисел с плавающей запятой в один 32-битный регистр с помощью функции __builtin_amdgcn_cvt_pkrtz, что значительно ускоряет преобразования между форматами и снижает накладные расходы при подготовке данных к умножению. В официальных примерах приводится детальный разбор загрузки данных для матриц A и B с учетом распределения элементов по нитям волнового фронта, что позволяет минимизировать необходимость в избыточных операциях и гарантировать согласованность данных для матричного умножения. Помимо базовых операций, возможности матричных ядер RDNA 4 успешно применяются в более комплексных задачах, таких как реализация многослойных перцептронов (MLP).
На примере упрощенной модели с входным, скрытым и выходным слоями, каждый из которых имеет размерность 16, показано, как можно эффективно выполнять последовательные GEMM операции с использованием WMMA-интринсиков. Важным преимуществом новой архитектуры является упрощенное взаимодействие между результатами одной операции и входными данными для следующей. В отличие от RDNA 3, где требовалась перестановка и обмен данными между потоками для приведения матриц к нужному формату, RDNA 4 избавлена от этой сложности за счет упрощенного формата VGPR, что заметно упрощает написание эффективных ядер и повышает общую производительность. Для разработчиков, заинтересованных в применении RDNA 4 матричных ядер, особое значение имеет доступность открытых SDK и примеров, обеспечивающих наглядные шаблоны кода, а также использование динамических библиотек Orochi, которые упрощают интеграцию HIP и CUDA API, позволяя создавать кроссплатформенные решения и более гибко управлять ресурсами GPU. Несмотря на все преимущества, использование матричных ядер накладывает определенные ограничения, например, размер обрабатываемых блоков фиксирован на уровне 16x16.
Для обработки больших матриц необходимо разбивать вычисления на соответствующие блоки и реализовывать логику составления итогового результата из частичных результатов блоков, что требует внимательного подхода к оптимизации памяти и вычислительной нагрузки. В свою очередь, разработчикам рекомендуется изучать официальное руководство по архитектуре AMD RDNA 4, где подробно описаны инструкции, форматы данных и рекомендации по оптимальному использованию матричных ядер. С учетом возрастающей роли AI и глубоких нейронных сетей в современных приложениях, новая технология AMD становится важной составляющей инструментов для создания эффективных, высокопроизводительных программных продуктов. В целом, AMD RDNA 4 с ее третьим поколением матричных ядер задает новые стандарты в области графических процессоров, объединяя прорывные аппаратные решения с удобным программным интерфейсом. Это мощное сочетание позволяет значительно ускорять вычисления с матрицами, что важно как для геймеров и разработчиков игр, так и для исследователей и инженеров, работающих с искусственным интеллектом и высокопроизводительными вычислениями.
Разработка и внедрение WMMA-интринсиков упрощает создание эффективных HIP ядер, а использование новых форматов распределения данных в регистрах снижает накладные расходы и повышает общую производительность. В результате архитектура AMD RDNA 4 становится привлекательным выбором для разработчиков, стремящихся внедрить современные методы ускорения матричных операций и раскрыть потенциал GPU в своих приложениях.