Современные языковые модели сталкиваются с огромными вызовами при работе с длинными текстовыми контекстами. С увеличением объема вводимой информации повышается нагрузка на вычислительные ресурсы, а также увеличивается время генерации ответов. Особенно остро эта проблема проявляется в ситуации, когда необходимо одновременно учитывать большой объем данных, например, в случае с массивными кодовыми репозиториями или обширными научными публикациями. В подобных задачах объем кеша ключ-значение (KV cache), который хранит промежуточные вычисления для ускорения вывода, растет экспоненциально, что становится узким местом в производительности моделей. Именно здесь на арену выходит инновационный подход, известный под названием «Cartridges» — специализированные маленькие KV-кэши, обученные с помощью метода self-study (самообучения), способные компактно и эффективно представлять большие корпуса текстовой информации.
Концепция cartridges — это революция в способах представления длинных контекстов для языковых моделей. Основная идея заключается в том, чтобы не подавать всю текстовую информацию напрямую в модель во время вывода, а предварительно создать небольшие, но информативные кэши, которые будут содержать сжатое и релевантное представление исходного корпуса. Такой подход позволяет значительно снизить издержки на обработку, не теряя при этом качество и полноту передаваемой информации. Метод self-study выступает ядром тренировки таких карт памяти. Его суть состоит в генерации синтетических диалогов на основе исходного текста, где две ИИ-агенты взаимодействуют между собой: один задает вопросы или запросы, а другой отвечает, опираясь на предоставленный контекст.
Через этот процесс модель научается лучше интерпретировать и структурировать информацию, что в конечном итоге позволяет формировать компактные KV-кэши с высоким уровнем содержания данных. Обучение cartridges разбито на несколько важных этапов. Для начала осуществляется синтез обучающих данных с помощью специально подготовленного скрипта, который работает через сервер инфернса, например, Tokasaurus. Здесь на основе исходного корпуса создаются разнообразные и качественные тренировочные примеры, имитирующие реальное взаимодействие с текстом. После этого происходит этап контекстной дистилляции — процесс непосредственного обучения самого кэша на сгенерированных данных, где модель учится предсказывать ответы и формировать эффективные представления.
Инфраструктурно проект поддерживает несколько способов развертывания — локально и в облаке с использованием Modal. Особенностью Modal является возможность быстрого горизонтального масштабирования и параллельного запуска множества GPU-инстансов, что существенно сокращает время обучения и облегчает экспериментирование с разными параметрами тренировки. Одним из ключевых параметров является начальная инициализация KV-кэша. В репозитории присутствуют несколько стратегий, начиная от случайного заполнения текстовыми или векторными представлениями до использования уже предобученных моделей. Чаще всего оптимальным выбором выступает инициализация случайным текстом, что обеспечивает хороший баланс между размером кэша и качеством результата.
Для оценки эффективности обученных cartridges применяются два основных вида валидации — по потере (loss) и генеративные оценки. Первая метрика анализирует, насколько хорошо модель с кэшем предсказывает ожидаемые ответы на тестовых наборах, измеряя перплексию. Вторая же оценивает качество генерируемого текста при ответах на заданные запросы, позволяя вручную инспектировать результаты через специально интегрированные инструменты визуализации, например, WandB. Одной из сильных сторон технологии является возможность использования разных типов «ресурсов» — объектов, через которые происходит подача данных для обучения cartridges. Среди поддерживаемых форматов есть стандартные текстовые файлы, специализированные LaTeX-файлы, данные из корпоративных мессенджеров вроде Slack или даже почтовых сервисов.
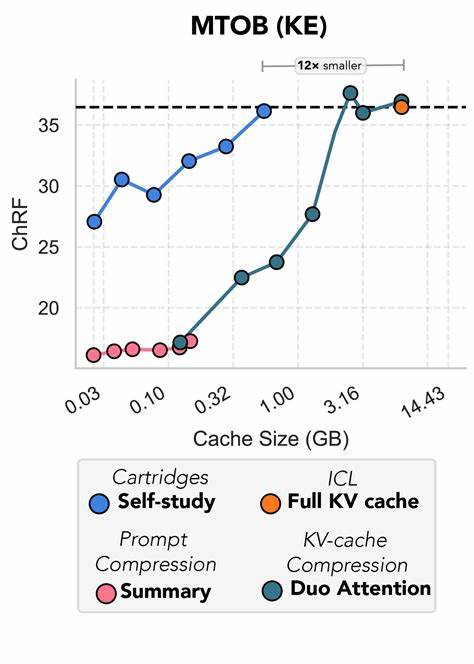
Такая универсальность расширяет область применения подхода от научных и технических текстов до деловых коммуникаций и переписки. На практике cartridges позволяют существенно повысить производительность генерации при работе с большими текстами. Уменьшая размер KV-кэша в десятки раз, они обеспечивают ускорение ухода от 10 до 26 раз, что открывает новые возможности для интерактивных и масштабируемых приложений на базе языковых моделей. При этом качество выдачи остается конкурентоспособным с более ресурсоемкими классическими решениями. В сценариях обслуживания и интеграции готовых cartridges предусмотрены разные решения, включая простой режим через PyTorch-генерацию и высокоскоростной вызов через сервер Tokasaurus.
Последний, благодаря оптимизациям и специальным API, позволяет быстро доставлять ответы с учетом контекста, хранящегося непосредственно в cartridges. Русскоязычное сообщество получает возможность познакомиться с этой перспективной технологией, которая уже открывает новые горизонты в области обработки естественного языка. Ключевым преимуществом cartridges и self-study выступает возможность хранения долгих контекстов компактно, что критично для развития умных помощников, аналитических систем и средств автоматизации. Немаловажной деталью является открытый исходный код проекта, опубликованный на GitHub, что обеспечивает прозрачность, гибкость настройки, а также возможность совместного развития и внедрения новых идей сообществом. Несмотря на многообещающие результаты, разработчики признают существующие сложности и активно работают над устранением некоторых известных проблем, например, связанных с параллельным обучением в распределенных системах.