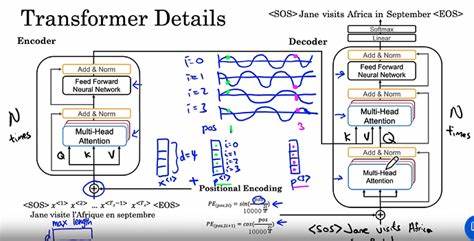
Современные трансформеры стали основой для многих прорывных достижений в области искусственного интеллекта, включая обработку естественного языка и компьютерное зрение. Одной из ключевых особенностей трансформеров является их способность эффективно обрабатывать последовательные данные без использования рекуррентных структур. Центральное значение в этом процессе занимают позиционные кодировки. Они позволяют модели учитывать порядок элементов во входной последовательности, обеспечивая тем самым понимание контекста и зависимости. Несмотря на широкое использование, теоретическое понимание влияния различных методов позиционного кодирования на выразительность, способность к обобщению и экстраполяцию моделей трансформеров остается ограниченным.
Новое исследование, проведенное в 2025 году, предлагает глубокий теоретический анализ этого аспекта, раскрывая, как разные подходы к позиционному кодированию влияют на ключевые характеристики трансформеров. Традиционные методы позиционного кодирования включают синусоидальные функции, обучаемые параметры и методы относительного позиционирования. Каждый из них имеет свои преимущества и ограничения. Синусоидальные функции обладают бесконечной экстраполяционной способностью, позволяя моделям обрабатывать последовательности большей длины, чем те, на которых они обучались. Однако у них есть ограничения в тонком захвате сложных зависимостей.
Обучаемые позиционные кодировки обладают гибкостью и позволяют модели подстраиваться под конкретные задачи, но они склонны к переобучению на фиксированных длинах и плохо обобщаются на более длинные последовательности. Относительные позиционные кодировки содействуют улучшению устойчивости к вариациям длины ввода, а методы, основанные на смещениях, такие как Attention with Linear Biases (ALiBi), вводят специальное смещение внимания, стимулирующее модель к фокусировке на ближайших элементах, что способствует лучшей экстраполяции. Представленная теоретическая рамка исследует некоторые фундаментальные свойства этих методов в контексте аппроксимационной мощности и оценки обобщающей способности через сложность Радамашера. Аппроксимационная мощность отражает, насколько эффективно модель способна аппроксимировать целевые функции, заданные последовательностями. Теория показывает, что методы позиционного кодирования, основанные на ортогональных функциях, таких как вейвлеты и многочлены Лежандра, позволяют значительно расширить класс функций, аппроксимируемых трансформером.
Эти функции обеспечивают эффективное разложение сигнала на базисные элементы, что улучшает представление разнообразных структур в данных. Кроме того, использование ортогональных базисов способствует уменьшению корреляции между позиционными признаками, что, в свою очередь, снижает риск переобучения и улучшает обобщающую способность. Анализ обобщающей способности через сложность Радамашера позволяет оценить, насколько трансформер с конкретным типом позиционного кодирования способен сохранять качество работы на новых, ранее не встречавшихся данных. Результаты показывают, что применение ортогональных позиционных кодировок обеспечивает более низкие оценки сложности, чем традиционные методы, что свидетельствует о лучшем балансе между выразительностью и стабильностью модели. Экстраполяция — это ключевой аспект, определяющий способность трансформера работать с последовательностями большей длины, чем использованные при обучении.
Традиционные обучаемые позиционные кодировки часто испытывают серьезные проблемы с экстраполяцией, в результате чего производительность существенно падает при увеличении длины последовательности. В то же время методы, такие как ALiBi, демонстрируют высокую способность к экстраполяции благодаря введению линейных смещений, которые эффективно ограничивают влияние удаленных позиций. Новое теоретическое исследование обобщает этот подход в единую математическую модель, что позволяет систематически создавать и анализировать новые смещающие функции для улучшения экстраполяции. Практические эксперименты на синтетических задачах последовательной обработки подтверждают теоретические выводы. Модели, использующие позиционные кодировки, основанные на ортогональных преобразованиях, показывают улучшенные результаты как на обучающих последовательностях, так и при работе с более длинными входами.
Это подтверждает важность выбора правильного типа позиционного кодирования для повышения общей эффективности трансформеров. Представленные результаты имеют важное значение для развития искусственного интеллекта в целом. Поскольку трансформеры применяются в разнообразных сферах — от обработки естественного языка и машинного перевода до компьютерного зрения и анализа временных рядов — понимание принципов работы позиционных кодировок поможет улучшить архитектуры новых моделей и повысить их производительность в реальных условиях. Рекомендуемые направления исследований включают дальнейшее развитие ортогональных методов позиционного кодирования, расширение их на многомерные и сложные структуры данных, а также интеграцию с другими механизмами модели для дополнительного повышения адаптивности и устойчивости. Таким образом, теоретический анализ позиционных кодировок в трансформерах не только заполняет существующий разрыв в понимании фундаментальных принципов работы этих моделей, но и способствует разработке более мощных и универсальных алгоритмов для обработки последовательных данных.
Этот прогресс открывает новые горизонты для создания гибких, точных и эффективных систем искусственного интеллекта, способных решать комплексные задачи в разнообразных областях науки и техники.