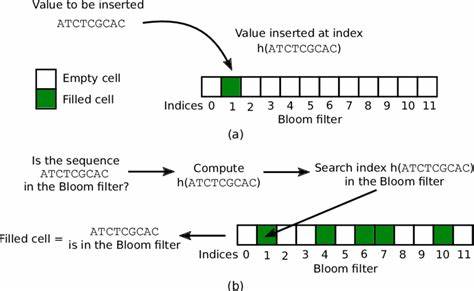
Фильтр Блума — это специализированный тип данных, предназначенный для быстрой и экономной по памяти проверки принадлежности элемента к определённому набору. В отличие от классических структур данных, таких как хэш-таблицы или деревья, фильтры Блума не хранят сами элементы, а лишь информацию о том, что элемент, скорее всего, присутствует в наборе. Основное преимущество такой техники — значительная экономия ресурсов при сохранении высокой скорости проверки. Как работает фильтр Блума? В его основе лежит битовый вектор — простой массив битов, которые изначально установлены в ноль. Чтобы добавить элемент, его пропускают через несколько различных хеш-функций, каждая из которых возвращает индекс в битовом векторе.
В этих позициях биты устанавливаются в 1. Проверка принадлежности работает аналогично — элемент хешируется теми же функциями, и если все соответствующие биты равны 1, фильтр сообщает, что элемент возможно присутствует в наборе. Если хотя бы один бит равен 0 — элемент точно отсутствует. Главной особенностью фильтра Блума является его вероятностный характер. Он никогда не скажет, что элемент присутстует в наборе, если это не так, но может ошибочно указать на наличие, когда элемент не был добавлен.
Это называется ложноположительным результатом. Вероятность таких ошибок зависит от параметров фильтра, таких как размер битового вектора, количество используемых хеш-функций и количество добавленных элементов. Выбор правильных хеш-функций — ключевой момент при построении фильтра Блума. Они должны быть независимыми, равномерно распределёнными и максимально быстрыми в вычислении. Множество криптографических алгоритмов, таких как sha1 или md5, обычно не подходят из-за их сравнительно высокой вычислительной нагрузки.
Вместо этого широко применяются специальные быстрые хеши, например, murmur, fnv, xxHash или HashMix, которые обеспечивают хорошее качество распределения и минимальные накладные расходы. Практика использования фильтров Блума разнообразна и охватывает множество областей. Они популярны в сетевых приложениях для фильтрации запросов, где важно быстро отбрасывать запросы с недопустимыми параметрами без необходимости обращаться к основным базам данных. Примеры включают кеширование веб-страниц, предотвращение повторных запросов, системы рекомендаций и многое другое. В биоинформатике фильтры применяются для быстрого поиска совпадений в больших наборах биологических данных, что повышает эффективность анализа геномов и других биомолекул.
Оптимальное соотношение параметров фильтра Блума требует внимательного подхода. При заданном количестве элементов и размере битового вектора можно вычислить количество хеш-функций, минимизирующих вероятность ложноположительных срабатываний. Принцип таков: слишком много хеш-функций замедляет работу и повышает вероятность заполнения битового вектора слишком быстро, слишком мало — увеличивает количество ложноположительных ошибок. Математически оптимальное количество хешей приблизительно равно (m/n) ln 2, где m — количество битов в векторе, а n — число элементов. Важным аспектом является масштабируемость фильтров Блума.
Классический фильтр рассчитан на фиксированное количество элементов. Если их становится больше, точность резко падает. Поэтому в реальных системах часто используются вариации — масштабируемые фильтры Блума, которые динамически расширяются по мере роста набора. Они сохраняют контролируемый уровень ложноположительных результатов, что делает их пригодными для крупномасштабных приложений. С точки зрения производительности фильтры Блума обладают высокой скоростью как при вставке элементов, так и при проверке.
Обе операции требуют выполнения нескольких хеш-функций и доступа к битам — это операции с постоянной и минимальной временной сложностью, не зависящей от размера полного набора данных. Также фильтры являются гораздо более компактными, чем хранение всех элементов напрямую, что критично для систем с ограниченной памятью. Некоторые известные проекты и технологии используют фильтры Блума в своих ядрах. Например, популярные базы данных и системы кеширования, такие как RedisBloom или RocksDB, интегрируют фильтры для ускорения поиска и уменьшения нагрузки на хранилища. Web-браузер Chromium применяет фильтры для оптимизации сетевых запросов.
Аналитические движки, такие как Apache Spark, тоже используют фильтры Блума для ускорения запросов и уменьшения затрат на передачу данных. Несмотря на огромное количество преимуществ, фильтры Блума имеют и ограничения. Основное из них — невозможность удаления элементов без полного пересоздания структуры. Если элемент попал в фильтр, а впоследствии требуется его исключить, это может привести к ошибкам или необходимости создания нового фильтра. Для решения подобных задач существуют расширения, например, счетные фильтры Блума, которые позволяют изменять количество добавленных элементов.
В заключение, фильтры Блума — мощный инструмент для алгоритмического творчества с огромным потенциалом в самых разных сферах. Их способность за минимальные ресурсы и с высокой скоростью обрабатывать огромное количество данных делает их неотъемлемой частью современных технологий. Правильный выбор параметров и понимание внутренних механизмов обеспечивают эффективное применение и позволяют добиться баланса между быстродействием и точностью. Если вы заинтересованы в ускорении обработки данных или снижении затрат на хранение, изучение и внедрение фильтров Блума станет важным шагом в развитии ваших проектов.

![Blocker Ring Synchromesh Unit – How It Works (Animation) [video]](/images/26FBD024-90B5-451F-8E83-15E293568F86)