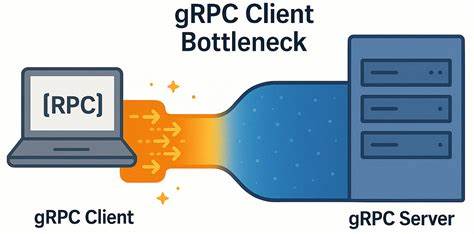
В современном мире распределённых систем и микросервисов gRPC стало одной из ключевых технологий для организации высокопроизводительного и надёжного взаимодействия между сервисами. Благодаря своей реализации поверх протокола HTTP/2, gRPC обеспечивает эффективную транспортировку удалённых вызовов процедур (RPC), поддержку потоков и множество полезных возможностей для масштабируемости и отказоустойчивости. Тем не менее, даже при использовании таких современных средств в системах с очень низкой сетевой задержкой можно встретиться с неожиданными проблемами производительности. Одна из таких проблем — узкое место именно на стороне клиента, способное существенно ограничить пропускную способность и увеличить время отклика приложений. В основе проблемы лежит ограничение, связанное со способом организации каналов и потоков RPC внутри единственного TCP-соединения, что ведёт к неожиданному увеличению клиентской латентности и уменьшению выгод от оптимальной сетевой инфраструктуры.
В данной статье рассматривается глубокий разбор этого явления, основанный на реальных замерах и бенчмарках, а также пути его решения, позволяющие извлечь максимум из возможностей gRPC в условиях низколатентных сетей. Для начала стоит кратко вспомнить, как устроен gRPC с точки зрения сетевого взаимодействия. gRPC-клиент использует один или несколько каналов (channels) для связи с сервером. Каждый канал — это своего рода абстракция, которая содержит внутри себя по одному или нескольким TCP-соединениям. Поверх TCP-транспорта gRPC работает с протоколом HTTP/2, внутри которого RPC-вызовы представлены отдельными потоками (streams).
Таким образом, несколько параллельных запросов могут мультиплексироваться по одному TCP-соединению с помощью HTTP/2. Официальная документация gRPC и best practices указывают, что существует ограничение по количеству одновременных активных потоков (concurrent streams) в рамках одного HTTP/2 соединения — по умолчанию около 100. Если этот лимит исчерпывается, дополнительные запросы ставятся в очередь на клиенте и ждут освобождения потоков. Для приложений с интенсивным нагрузочным профилем или длительными потоковыми вызовами это может стать узким местом. Одна из рекомендаций — создавать отдельные каналы для различных областей высокой нагрузки или использовать пул каналов с разными конфигурациями, чтобы распределить запросы по нескольким соединениям и избежать очередей.
Команда разработчиков YDB столкнулась с любопытным феноменом: при уменьшении количества серверных узлов в кластере и одновременно оставляя нагрузочные генераторы без изменений, они заметили снижение общей пропускной способности и рост клиентских задержек. В частности, даже при наличии свободных ресурсов на стороне сервера, клиентские задержки существенно увеличивались, а загрузка процессоров снижалась. Это навело их на мысль о том, что узкое место может скрываться именно внутри клиентской реализации gRPC вследствие особенностей управления TCP-соединениями и HTTP/2. Для более глубокого анализа была реализована простая gRPC-микробенчмарка на C++, которая позволяет экспериментировать с параметрами параллелизма и каналов на стороне клиента и сервера. Серверная часть использовала асинхронный API gRPC с несколькими очередями завершения и рабочими потоками, оптимально распределёнными по NUMA-ноду, что минимизирует накладные расходы на переключение контекста и кэш-промахи.
Клиент запускался с переменным числом воркеров, каждый из которых использовал собственный канал для вызовов gRPC, но без особой настройки уникализации каналов. Тестовые машины были связаны скоростным 50 Гбит/с каналом с крайне низкой задержкой в районе 40–50 микросекунд. Результаты экспериментов оказались показательными. При увеличении количества параллельных запросов (in-flight) суммарная пропускная способность растёт далеко не линейно, как можно было бы ожидать при низкой сетевой латентности и высокой мощности вычислительных ресурсов. При небольшом увеличении нагрузки наблюдался значительный рост латентности, который ограничивал общее быстродействие.
Анализ трафика tcpdump подтвердил, что все вызовы мультиплексируются и проходят по одному TCP-соединению, что обеспечивает лишь одну точку возможного узкого места. При детальном исследовании выявился значительный простой на стороне клиента между подтверждением последнего пакета от сервера и отправкой следующего запроса, порядка 150–200 микросекунд. В реальности был отмечен так называемый «client-side batching» — когда клиент ждёт освобождения возможности отправить данные по одному потоку HTTP/2, в результате чего вводится задержка, которая накапливается и негативно влияет на скорость передачи данных. Примечательно, что попытки использовать по одному каналу на каждого воркера без дополнительных настроек не приводили к улучшению — TCP соединение оставалось единым. Переломным моментом стало использование нескольких каналов с уникальными параметрами, что заставляет gRPC создавать отдельные TCP-соединения для каждого канала.
Кроме того, активация специального флага GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL позволила добиться распределения нагрузки и явного разделения потоков по разным соединениям. В итоге это привело к многократному улучшению пропускной способности и значительному снижению задержек, приближаясь к теоретически идеальной масштабируемости. Именно эта неожиданная особенность — скрытая очередность и ограничение в рамках одного TCP-соединения с HTTP/2, невидимая со стороны пользователя, но критичная для масштабируемости latency-sensitive приложений — стала ключевым выводом. В средах с очень низкой сетевой задержкой такой клиентский узкий горлышко становится доминирующим фактором, который подавляет ожидаемый выигрыш от быстрой сети и мощного оборудования. При переходе к сетям с повышенной латентностью, например порядка 5 миллисекунд, влияние такой проблемы заметно снижается.
В этих условиях задержка связи становится главным фактором общего времени отклика, а влияние внутренней организации каналов gRPC уменьшено. Однако в современных дата-центрах, облачных средах и высокопроизводительных кластерах с низкой сетевой латентностью обход этого узкого места необходим для реального повышения эффективности. На практике это означает, что разработчикам распределённых систем и микросервисных архитектур при использовании gRPC следует внимательно подойти к организации клиентской части. Следует помнить, что создание множества каналов с уникальными параметрами и использование пулов каналов, как минимум с включённой поддержкой GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL, позволит разбить нагрузку по нескольким TCP-соединениям и значительно снизить задержки. Это особенно важно для приложений с необходимостью обработки большого числа параллельных краткоживущих запросов.
Для поддержки высокой производительности необходимо также учитывать аффинити потоков к определённым CPU-ядер и NUMA-ноду, оптимизировать настройки очередей завершения и ограничить накладные расходы контекстных переключений. Использование современных инструментов профилирования и трассировки на уровне сетевого стека и самого gRPC позволит своевременно выявить узкие места. В заключение стоит подчеркнуть, что успех эксплуатации gRPC в латентносенситивных системах с высокими требованиями к пропускной способности и времени ответа зависит не только от правильной настройки сетевого окружения и серверной части, но и от детального понимания внутренней архитектуры клиента. Применение рекомендаций по распределению каналов и потоков RPC избавит от «невидимых» узких мест и позволит максимально раскрыть потенциал современных высокоскоростных сетей и вычислительных ресурсов. Комьюнити gRPC продолжает развиваться, и возможны появление новых оптимизаций и техник, которые смогут ещё глубже улучшить производительность и масштабируемость этой технологии.
Важно следить за обновлениями и регулярно перепроверять конфигурации под свои уникальные сценарии работы.