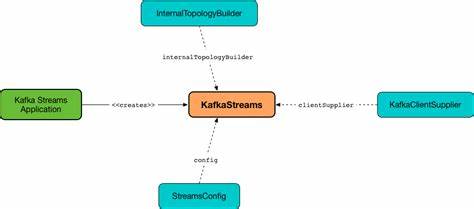
Kafka Streams – это мощная библиотека для обработки потоков данных в реальном времени, встроенная в экосистему Apache Kafka. Ее главная задача – упростить разработку приложений, которые работают с огромными объемами непрерывно поступающих данных, обеспечивая при этом масштабируемость, отказоустойчивость и минимальные задержки. В современных условиях, когда обработка данных становится неотъемлемой частью бизнес-процессов, понимание внутренних механизмов Kafka Streams приобретает особую важность для разработчиков и инженеров данных. В основе Kafka Streams лежит концепция построения топологии обработки данных в виде направленного ациклического графа (DAG). Такой подход подразумевает, что данные проходят через последовательность узлов, каждый из которых выполняет определенную функцию: чтение из источников, трансформации, агрегирование и запись в конечные хранилища.
Источниками в данном случае служат топики Kafka, которые поставляют непрерывные потоки сообщений. Одним из ключевых компонентов является Processor API – низкоуровневый интерфейс, позволяющий создавать кастомную логику обработки данных. С его помощью разработчики могут работать с каждым сообщением индивидуально, взаимодействуя с контекстом обработки, имеющим доступ к метаданным, таким как тема, раздел и временная метка. Доступ к локальным хранилищам состояния позволяет реализовывать сложные stateful операции, необходимы для агрегаций, оконных вычислений и других задач. Высокоуровневый DSL предоставляет богатый набор абстракций для типичных операций над потоками, таких как фильтрация, объединение и подсчет.
Он упрощает описание потоков, компилируя декларативные выражения в топологию процессоров под капотом. Эта интеграция позволяет балансировать между удобством разработки и гибкостью точной настройки производительности. С точки зрения масштабирования Kafka Streams построена на использовании потребительских групп Kafka. Каждый экземпляр приложения с одинаковым application.id распределяет нагрузку по задачам, в соответствии с количеством партиций топиков.
Такой подход гарантирует, что каждый обработчик работает только с выделенной ему частью данных, что позволяет горизонтально масштабировать систему без накладных расходов на сложную координацию. Важнейшим аспектом является управление состоянием. Kafka Streams сохраняет локальные состояния в специальных state stores, которые могут реализовываться как в памяти, так и на основе дисковых баз данных, например RocksDB. Благодаря созданию changelog топиков, хранящих все изменения состояния, система быстро восстанавливается после сбоев путем пересоздания состояния из этих журналов. Режим работы Kafka Streams организован вокруг StreamThread – потоков исполнения, которые управляют жизненным циклом задач обработки.
Каждый поток содержит один или несколько активных StreamTask, обрабатывающих сообщения из назначенных партиций. Потоки активно взаимодействуют с координационным механизмом Kafka для отслеживания изменений partition assignment и обеспечения сбалансированной обработки. Процесс работы одного потока включает циклы опроса потребителя, обработки сообщений, выполнения периодических действий (пунктуация) и фиксации прогресса (commit). Пунктуация играет роль таймера для запуска периодических процессов – например, вывода результатов агрегаций или очистки устаревших данных. Такой механизм помогает гибко управлять временем жизни вычислений.
Важный архитектурный элемент – разделение топологии на подграфы, связанных через промежуточные топики. Это позволяет создавать масштабируемые и независимые субтопологии, которые можно разворачивать и перезагружать без остановки всей системы. В случае сложных многокомпонентных обработок такой подход повышает общую надежность и устойчивость к ошибкам. Сериализация и десериализация играют ключевую роль при обмене сообщениями между узлами. SourceNode отвечает за получения и десериализацию данных из топиков, а SinkNode – за сериализацию и отправку конечных результатов обратно в Kafka.
При этом применяется гибкий механизм выбора партиций для записи, позволяющий оптимизировать распределение нагрузки и поддерживать корректный порядок сообщений. Кроме того, Kafka Streams предоставляет инструменты мониторинга и метрик, облегчающие отладку и настройку приложений. Встроенная интеграция с Kafka Admin API позволяет получать состояние кластеров и оперативно реагировать на изменения или сбои. В итоге, Kafka Streams представляет собой тщательно продуманное решение для построения распределенных потоковых приложений с сохранением состояния и гарантией обработки «ровно один раз». Его архитектура включает надежные механизмы масштабирования, восстановления после сбоев и поддержки сложных вычислительных сценариев.
Понимание внутренностей Kafka Streams открывает возможности для оптимизации производительности, настройки отказоустойчивости и более эффективной разработки приложений, работающих с потоками данных. Глубокое знакомство с такими понятиями, как топологии, процессоры, state stores, task assignment и потоками исполнения, позволяет создавать решения, максимально использующие потенциал Kafka при обработке данных в реальном времени. Разработка на базе Kafka Streams приносит значительные преимущества для бизнеса, позволяя создавать системы, которые быстро реагируют на изменения, интегрируются с экосистемой больших данных и легко масштабируются по мере роста нагрузки. Погружение в детали реализации помогает не только понять, как работает технология, но и как ее адаптировать под специфические задачи и требования. Kafka Streams – это не просто библиотека, а мощный каркас для работы с потоками, который обеспечивает баланс между простотой использования и контролем над процессами.
Такие свойства делают ее привлекательным выбором для разработки современных распределенных приложений, ориентированных на обработку событий и онлайн-аналитику. Внутренние механизмы Kafka Streams – это сложный, но логичный и хорошо организованный комплекс, изучение которого позволяет повысить мастерство и качество создаваемых решений.