В современной практике анализа данных и машинного обучения проблема пропущенных значений встречается очень часто и порой становится критической для построения качественных моделей. Потеря даже небольшой доли информации может вести к искажённым результатам, снижению точности предсказаний и ухудшению аналитической ценности. В связи с этим разработка эффективных алгоритмов иммутации - процессов восстановления или заполнения пропущенных данных - является одной из ключевых задач статистики и науки о данных. Среди множества подходов особое внимание заслуживает метод kNNSampler, который получил широкое признание благодаря своей способности не просто восстанавливать усреднённые значения, а восстанавливать целые распределения пропущенных величин в стохастическом режиме. Данная технология предлагает новый взгляд на проблему иммутации, значительно расширяя возможности анализа и прогнозирования в условиях неполноты информации.
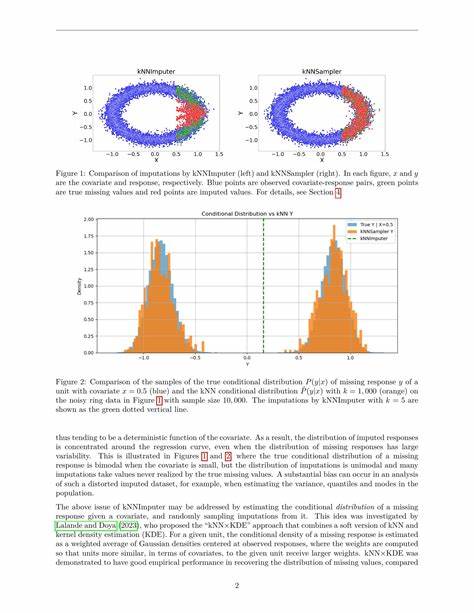
В основе метода лежит идея использования ближайших соседей (k Nearest Neighbors) - единиц данных, наиболее похожих на объект с пропущенными значениями по наблюдаемым признакам. В отличие от классических методов, например, известного kNNImputer, который подставляет в пропущенные ячейки условное математическое ожидание (среднее) ответа при заданных признаках, kNNSampler производит случайную выборку среди наблюдаемых ответов этих ближайших соседей. Этот принцип позволяет восстанавливать не просто фиксированное приближённое значение, а целую вероятностную структуру - условное распределение пропущенного параметра при известных ковариатах. Такая стохастическая иммутация имеет огромное значение для понимания и учета неопределённости, присущей отсутствующим данным. Она делает возможным многократное заполнение (multiple imputation), где для каждого пропуска генерируется множество реализаций, что в дальнейшем повышает надежность и воспроизводимость статистических выводов и результатов машинного обучения.
Одним из ключевых достоинств kNNSampler является его простота и интуитивная понятность. Метод не требует построения сложных математических моделей или предположений о форме распределения данных, что часто бывает проблематично в реальных задачах с неоднородными и сложными структурами. Вместо этого алгоритм опирается на эмпирическую выборку, используя найденных ближайших соседей и случайный процесс выборки из их наблюдаемых ответов. Это обеспечивает высокую гибкость и адаптивность к разнообразным типам данных, а также гарантирует, что иммутация отражает реальные вариации и разброс значений, присущие исходным данным. Экспериментальные исследования показали, что kNNSampler превосходит традиционные методы, особенно в условиях, когда пропуски являются не просто случайными, а зависят от нефиксированных факторов.
В таких случаях средние значения не дают полной картины, а способность оценивать распределения выводит качество анализа на новый уровень, позволяя адекватно учитывать все возможные варианты продолжения и восстановление природы данных. Кроме того, метод положительно воспринимается с точки зрения вычислительной эффективности. В отличие от комплексных моделируемых алгоритмов, создающих вероятность отсутствующих значений через генеративные сети или сложные байесовские модели, kNNSampler опирается на простую операцию поиска соседей и случайного выбора, что существенно уменьшает затраты времени и ресурсов, сохраняя при этом высокую точность и степень адекватности иммутации. Внедрение kNNSampler особенно актуально для разнообразных областей. В медицинских исследованиях наличие неполных данных может искажать результаты диагностических моделей и прогнозов, в финансовых данных пропуски способны приводить к неверным оценкам рисков, в социальных и маркетинговых науках корректная работа с неполными данными помогает точно выявлять тренды и предпочтения аудитории.
Использование стохастической иммутации позволяет получать более устойчивые и объективные результаты во всех этих сферах. Научно-исследовательский коллектив, стоящий за разработкой метода, опубликовал подробные описания и исходный код, что способствует широкому применению и адаптации алгоритма в различных программных средах и аналитических платформах. Это значит, что любую современную систему обработки данных можно быстро оснастить новым мощным инструментом для более корректной работы с пропущенными значениями. В заключение, kNNSampler - это качественно новый шаг в области обработки неполных данных, обеспечивающий не просто исправление пробелов, а полноценное понимание и моделирование неопределённости вокруг них. Этот метод открывает путь к более точному, обоснованному и ответственному анализу данных, позволяя специалистам и исследователям принимать решения на основе полноценных вероятностных моделей, а не усреднённых приближений.
В условиях растущих объемов и сложности информации необходимость подобного подхода становится все более очевидной и востребованной. Внедрение kNNSampler свидетельствует о зрелости и инновационности развития статистических методов, подтверждая, что будущее работы с данными - за адаптивными, стохастическими и приближёнными к природе процессов заполнения данных системами. Это однозначно заслуживает внимания всех, кто заинтересован в точном, надёжном и современном анализе данных в условиях реального мира со всеми его ограничениями и сложностями. .

![1994: Are You Ready for the Internet? – Tomorrow's World Retro Tech BBC Archive [video]](/images/ED79FD7D-1DAD-423A-AA77-8E404A913AD3)