Современные вычисления все больше зависят от возможностей графических процессоров (GPU), которые обеспечивают высокую производительность в задачах машинного обучения, научных расчетах и обработке мультимедиа. Вместе с ростом применения GPU растет потребность в эффективной технологии сохранения и восстановления состояния рабочих процессов, особенно когда речь идет о длительной работе, отказоустойчивости и оперативной миграции приложений между серверами. Одним из популярных инструментов для таких задач является CRIU (Checkpoint/Restore In Userspace) — многообещающая технология для заморозки и возобновления процессов пользователя. Однако интеграция GPU в эти механизмы сталкивалась с особенностями аппаратного и драйверного взаимодействия, что приводило к техническим вызовам и узким местам в производительности. Последние разработки предлагают инновационные решения для параллельного восстановления GPU, которые радикально меняют подход к этому процессу, повышая скорость и снижая задержки.
В данном материале мы подробно рассмотрим суть технологии, проблемы, которые ставит вектор GPU, и способы их решения с помощью нововведений в CRIU, особенно на примере AMD GPU и драйверного стека AMDGPU. Технология checkpoint/restore (снятие контрольной точки и последующее восстановление) изначально задумывалась как средство для фиксации состояния процесса в определенный момент с возможностью его возобновления позже, возможно, и на другом оборудовании или в другом месте. Такая методика крайне важна для обеспечения высокой отказоустойчивости, позволяя «замораживать» выполнение вычислительных задач и возобновлять их при сбоях, а также для организации live-миграции процессов на новые узлы без необходимости повторного запуска приложений с нуля. При этом традиционные подходы хорошо работают для CPU-интенсивных задач, но столкнулись с серьезными проблемами при работе с GPU. Основная сложность восстановления GPU-состояний кроется в уникальности архитектур и внутреннего состояния видеокарт разных производителей.
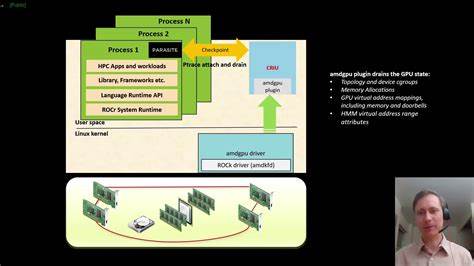
В отличие от CPU, состояние GPU зачастую сложно или даже невозможно получить или восстановить стандартными средствами в пользовательском пространстве. В частности, драйверы для AMD и NVIDIA имеют собственные механизмы управления памятью и внутренними буферами, а также аппаратно-софтовые особенности, обуславливающие различные подходы к сохранению и восстановлению состояния. CRIU решил эту проблему посредством внедрения плагинов, то есть динамически загружаемых библиотек с индивидуальной логикой восстановления и сохранения состояния, специфичной для каждого производителя GPU. Эти плагины интегрируются в общий процесс checkpoint/restore через хуки — контролируемые точки вызова, где выполняется специализированный код. Для AMDGPU плагин использовал, прежде всего, DUMP_EXT_FILE на этапе создания снимка и RESTORE_EXT_FILE при восстановлении, на которых обрабатывались драйверные состояние и VRAM.
Ранее процесс восстановления состоял из ряда строго последовательных операций. После форка дочернего процесса-восстановления происходило восстановление дескрипторов файлов, статуса драйвера GPU, а также критически важного содержимого видеопамяти (VRAM), которое переносилось с помощью системного DMA. Затем шло восстановление хостовой памяти процесса, что требовало размонтиования всех прежних отображений памяти и наложения новых фрагментов из снимка. Этот этап осуществлялся внутри дочернего процесса, который переключался на специальный «restorer blob» — область безопасной памяти, чтобы не сбиваться самому. Такая последовательная схема приводила к существенным задержкам — пока происходило восстановление GPU-памяти, весь дочерний процесс был заблокирован, что не позволяло эффективно использовать ресурсы и ускорить процедуру.
Попытки распараллелить процесс восстановления прямо внутри дочернего процесса не приносили результата: при размонте памяти, необходимом для восстановления хостовой части, у дочернего процесса удалялись и библиотеки, которые могли все еще использоваться для GPU-операций, например libdrm или libc. Это вызывало конфликты и падения, поэтому привычная многопоточность внутри процесса была непригодна для решения задачи. Решением проблемы стало введение нового хука POST_FORKING, активируемого основной процесс CRIU сразу после форка дочернего процесса и перед ожиданием завершения восстановления. Именно в этот момент основной процесс получает возможность взять на себя восстановление содержимого GPU. Такой подход позволил выделить GPU-восстановление в отдельный поток, запускаемый в основном процессе, который параллельно с дочерним занимается восстановлением хостовой памяти.
Для успешного обмена данными между восстановительным и основным процессами была использована технология передачи дескрипторов dma-buf — особых файловых дескрипторов, позволяющих делиться буферами видеопамяти между процессами посредством Unix-сокетов. Дочерний процесс экспортирует объект памяти видеопамяти как dma-buf, передает его вместе с командами для восстановления основному процессу, который импортирует дескрипторы и начинает процедуру восстановления напрямую через системный DMA в отдельном потоке. Для адаптации AMDGPU-плагина пришлось переписать ключевые хуки. Ранее amdgpu_plugin_restore_file() занимался и метаданными, и передачей VRAM, теперь же он выступает в роли отправителя дескрипторов и состояния для основного процесса. Новый хук amdgpu_plugin_post_forking() запускает приемную ветвь в основном процессе, принимающую дескрипторы и непосредственно восстанавливающую GPU.
Еще один хук — amdgpu_plugin_resume_devices_late(), вызываемый в основном процессе уже после завершения хостового восстановления, служит синхронизационной точкой для гарантирования, что GPU-восстановление тоже окончено. Результат внедрения параллельного пути восстановления оказался впечатляющим. На платформе тестов восстановление приложений с GPU показало ускорение времени лечения снимка на 34,3 % при загрузке данных из памяти, и на 7,6 % при восстановлении с диска. Такие показатели говорят о реальной пользе для приложений с интенсивным использованием GPU, повышая общую отзывчивость и устойчивость вычислительных платформ. Перспективы развития технологии выглядят многообещающе.