С развитием технологий искусственного интеллекта современные языковые модели становятся всё более продвинутыми и способны генерировать тексты, которые по стилю и содержанию практически неотличимы от человеческих. Вопрос о том, какой из популярных ИИ пишет максимально похоже на человека, становится актуальным не только для специалистов в области обработки естественного языка, но и для широкой аудитории, заинтересованной в создании качественных контентов, будь то журналистика, маркетинг или творческое письмо. Одним из эффективных методов анализа текстов, позволяющих оценить сходство стиля написания ИИ и человека, является использование n-грамм - последовательностей из n подряд идущих слов, которые отражают локальные зависимости и характерные фразы. Этот подход помогает выявить уникальные паттерны и повторяемость стилистических элементов в текстах, созданных разными языковыми моделями и людьми. Принцип работы n-грамм заключается в том, что они разбивают текст на фрагменты определённой длины: биграммы (двухсловные сочетания), триграмы (трёхсловные), и так далее.
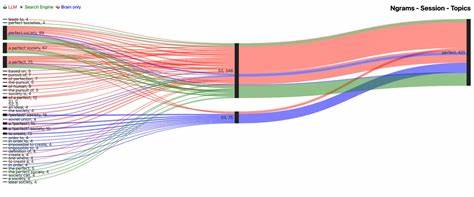
Анализ частотности и распределения таких фрагментов в тексте помогает понять, насколько язык ИИ вариативен, богаче или стереотипен по сравнению с человеческими текстами. Чем выше разнообразие и естественность употребления n-грамм, тем больше вероятность, что текст сгенерирован близко к человеческому стилю. Автор статьи, использовавший этот метод, организовал эксперимент, в ходе которого ему предлагалось написать небольшой текст по заданному описанию - в данном случае, описание мальчика с красным мячом и щенком в живописном повествовательном стиле с использованием описательного языка и разнообразных структур предложений. Цветущие детали и неожиданное событие в тексте усиливали его нарративный характер. После этого тот же самый текст был предложен различным языковым моделям, таким как ChatGPT, Gemini, Claude и другим, и их ответы были подвергнуты анализу с помощью n-грамм для выявления сходств и различий.
Итоги исследования показали, что некоторые языковые модели демонстрируют высокую сложность и вариативность лексических конструкций, приближаясь к естественному человеческому стилю, тогда как другие создают более шаблонные и повторяющиеся фразы, которые могут выдать их искусственную природу. Интересным оказался вопрос о целенаправленном управлении стилем генерации текста - можно ли подстроить ответы языковых моделей под определённый LLM, используя наводящие вопросы, примеры или корректировки запросов? Практика показывает, что языковые модели реагируют на тональность и формулировку инструкций, что позволяет адаптировать результаты генерации и приблизить их к нужному стилю. При вставке реальных ответов разных моделей в систему анализа n-грамм, наблюдается уровень сходства с человеческим письмом, который либо соответствует ожиданиям, либо удивляет - показывая, что некоторые ИИ превосходят предвзятые предположения, приближаясь к более естественному стилю. Этот подход может служить основой для дальнейшей оценки и обучения языковых моделей, направленных на улучшение качества создаваемых текстов и повышение доверия пользователей к ИИ-генерированному содержимому. Анализ n-грамм не только помогает в сравнении различных ИИ, но и играет важную роль в разработке антиспам-систем, инструментов проверки уникальности и предотвращении плагиата, что особенно важно в эпоху широкого распространения автоматического контента.
Практическое применение метода включает создание интерактивных тестов для пользователей, позволяющих оценить степень сходства их писательского стиля с различными языковыми моделями. Такие тесты стимулируют творческое мышление и дают возможность понять, насколько ИИ может имитировать индивидуальный стиль. В целом, использование n-грамм - мощный и доступный инструмент для анализа качества текстов и оценки потенциала языковых моделей создавать максимально человеческие по стилю и содержанию материалы. Эта методика продолжит играть важнейшую роль в развитии технологий искусственного интеллекта и в понимании того, каким образом машины представляют и воспроизводят человеческий язык в цифровую эпоху. .