Современные большие языковые модели (LLM) стали неотъемлемой частью множества приложений — от генерации текста до сложного решения задач с многократной передержкой информации. Однако одна из главных проблем заключается в ограничениях контекста, которые сдерживают эффективность и точность долгосрочного рассуждения. В традиционных LLM существует лимит на количество токенов, которые модель может обрабатывать одновременно, что создает узкое место в решении комплексных задач, требующих взаимодействия с большой информацией. Недавнее исследование, представленное в работе «Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning» и сопровождающееся созданием Thread Inference Model (TIM) и среды TIMRUN, предлагает революционное решение, способное изменить подход к работе с большими языковыми моделями и их возможностям долгосрочного рассуждения. В центре внимания разработчиков и исследователей – преодоление ограничений, связанных с хранением и обработкой данных в рамках единственного сеанса генерации текста.
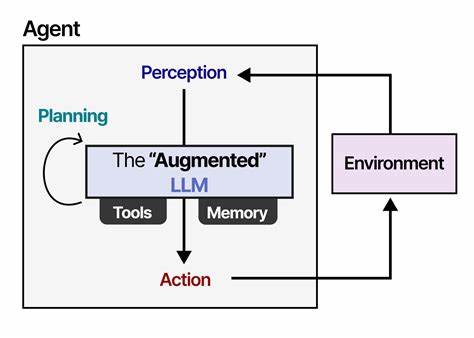
Новая методика опирается на представление естественного языка не как линейного потока текста, а в виде подобных дерева рассуждений, состоящих из задач, связанных мыслей, рекурсивных подзадач и выводов. Такой подход позволяет разделить сложную проблему на более мелкие, управляемые элементы, обеспечивая при этом эффективное управление памятью и ресурсами GPU. Главный прорыв TIM и TIMRUN кроется в инновационном механизме управления рабочей памятью: во время генерации модель по определённым правилам отсекает менее значимые подзадачи, сохраняя только ключевые состояния контекста в памяти. Такое подзадачное «обрезание» позволяет регулярно переиспользовать позиционные эмбеддинги и страницы памяти GPU, что существенно повышает пропускную способность инференса и сокращает нагрузку. Именно за счёт использования правил для фильтрации и выбора релевантных данных достигается возможность обрабатывать задачи с предельной глубиной и длиной, практически не ограниченной классическими лимитами контекста.
Кроме того, TIM и TIMRUN обеспечивают поддержку множественных вызовов внешних инструментов в рамках одного инференса, что расширяет функциональные возможности модели и позволяет ей решать задачи с многошаговым поиском и анализом. Эксперименты демонстрируют, что система способна стабильно и эффективно работать с большими объёмами ключ-значение кэша в GPU-памяти (до 90%), при этом сохраняется высокая производительность и точность в сложных математических задачах и проблемах, требующих последовательного получения и обобщения информации. Что касается самого процесса генерации, модель не опирается жёстко ни на глубинный, ни на ширинный обход дерева рассуждений. В субсообщениях в сообществе авторы отмечают, что структура выводов динамически формируется по мере авто-регрессивного генерирования, без предварительно заданных правил последовательности, с поддержкой вызова инструментов и подзадач в режиме реального времени. Такой адаптивный механизм позволяет системе «самокорректироваться» и гибко приспосабливаться к требованиям текущей задачи, решая проблему критических зависимостей между узлами и обеспечивая точное и релевантное выполнение плана.
Интерес к данной работе проявлен и в технологическом сообществе, где специалисты выражают надежду на то, что подобные решения в будущем позволят создавать полноценные ИИ-ассистенты с практически неограниченной памятью. Многие сталкиваются с неудобствами, когда приходится начинать новый сеанс чата из-за ограничений памяти, и TIM с TIMRUN обещают положить этому конец. По технической части команда разработчиков активно ведёт работу над открытием исходных данных и кода, периодически обновляя репозиторий и публикуя примеры, что говорит о заинтересованности поддержать интеграцию и дальнейшее развитие технологий в исследовательском и практическом сообществе. Уже сейчас можно опробовать TIMRUN с помощью доступного API на платформе subconscious.dev, что открывает новые горизонты для разработчиков, стремящихся внедрять долгосрочное рассуждение в свои приложения и сервисы.
Результаты исследования и данных о производительности демонстрируют большие перспективы этой методики: высокая точность в задачах, требующих многошагового анализа, сохранение ресурсов при работе с объёмными данными и комбинирование глубокого логического структурирования с гибкостью автогенерации. В будущем подобные подходы могут кардинально трансформировать способы взаимодействия с ИИ, позволяя создавать интеллектуальные системы, способные решать комплексные задачи без постоянного вмешательства и ограничений памяти. Thread Inference Model и среда TIMRUN задают новый стандарт для эффективного и масштабируемого долгосрочного рассуждения, открывая дверь в эру более продвинутых и автономных ИИ-рекомендателей, помощников и аналитических инструментов. Внедрение данных технологий сулит быстрый прогресс в области разработки ИИ с качественно улучшенными параметрами обработки информации, перспективами более масштабных проектов и широким спектром возможностей для бизнеса и науки. Независимо от того, занимаются ли специалисты математическими вычислениями, информационным поиском или сложной логической декомпозицией, современные решения в области LLM благодаря TIM и TIMRUN предлагают эффективный, инновационный и перспективный способ преодолеть давно существовавшие ограничения.
Индустрия ИИ стоит на пороге значительного скачка, и технологии, подобные описанным, играют ключевую роль в формировании будущего машинного интеллекта на основе глубокого, долгосрочного и контекстно-гибкого понимания языковых данных.