Современные системы обработки естественного языка и искусственного интеллекта стремительно развиваются, предлагая инновационные решения для повышения качества поиска и генерации ответов на сложные запросы. Одним из наиболее значимых достижений последних лет стало внедрение больших языковых моделей (LLM) в процессы планирования запросов в Retrieval-Augmented Generation (RAG). Это позволило добиться увеличения релевантности ответов почти на 40%, что является значительным улучшением по сравнению с традиционными методами. RAG — это технология, которая объединяет преимущества извлечения релевантного контента из различных источников с мощными возможностями генерации ответов на основе этих данных. Ключевая сложность в таких системах состоит в правильном формировании и планировании запроса, поскольку часто пользователи задают комплексные вопросы, требующие объединения информации из множества документов и источников.
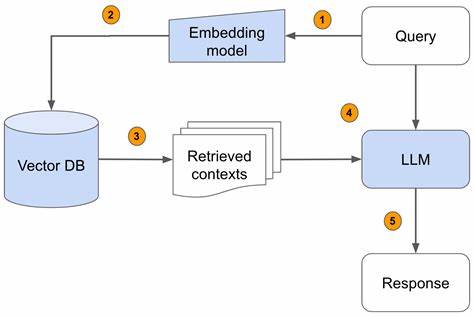
Обычные поисковые системы, основанные на простом извлечении и ранжировании документов, часто не способны должным образом обработать такие запросы, что приводит к снижению качества формируемых ответов. В этом контексте использование LLM для планирования запросов становится революционным инструментом. Большие языковые модели анализируют исходный пользовательский запрос, учитывают контекст диалога, исправляют ошибки и неправильные формулировки, а также формируют один или несколько преобразованных запросов, каждая из которых предназначена для оптимального поиска соответствующего контента. Такой подход называется агентным поиском и реализован в новом API Azure AI Search — Agentic Retrieval API. Agentic Retrieval API сочетает в себе несколько важных компонентов.
Во-первых, функция планирования запросов переводит сложный пользовательский запрос в набор более конкретных и целевых поисковых запросов. В процессе происходит исправление опечаток, генерация парафраз и интеграция контекста из истории взаимодействия с пользователем. Эта трансформация происходит всего за один вызов LLM, что обеспечивает минимальную задержку и экономию ресурсов. Во-вторых, система выполняет поисковые операции одновременно по нескольким сформированным запросам с использованием гибридного поиска — объединения классического текстового поиска и поиска по векторным представлениям. Далее документы проходят этап семантического ранжирования, который переставляет результаты в порядке релевантности, учитывая смысловую связь.
После этого происходит объединение, дедупликация и формирование единой текстовой строки с наиболее важным контентом для последующей генерации ответа. В итоге конечный пользователь получает ответ, созданный на основе тщательно отобранного и объединённого релевантного содержимого, без необходимости дополнительной обработки или фильтрации. Это значительно упрощает архитектуру приложений, повышает качество результата и снижает сложность интеграции. Проведённые Microsoft многочисленные эксперименты на реальных и синтетических наборах данных, содержащих сложные и простые запросы, показали впечатляющие результаты. Для сложных сценариев, когда запрос требует объединения данных из нескольких источников или содержит ошибки и неоднозначности, Agentic Retrieval API демонстрирует улучшение релевантности ответов по сравнению с традиционным поиском на 16-33 балла по шкале качества оценки, что эквивалентно примерно 40% повышению.
Это достижение особенно заметно в разнообразных областях и языках, включая немецкий, английский, испанский, французский, японский и китайский. Такой мультиъязычный охват делает решение универсальным и применимым в глобальных коммерческих и технических сервисах. Также стоит отметить важность оценки соблюдения достоверности информации — так называемой groundedness. Несмотря на трансформацию запросов и сложность формирования ответа, уровень groundedness новых ответов остается на уровне традиционных систем, что говорит о том, что модель не генерирует вымышленные данные, а строго основывается на найденных материалах. Технология Agentic Retrieval API позволила значительно повысить показатели для запросов различных типов: аналитических, сравнительных, контекстных, конверационных, а также запросов с опечатками и сложных многошаговых вопросов.
В каждом из этих случаев LLM-планирование запросов обеспечивает более точное извлечение информации, разбивая исходный запрос на логически связанные подзапросы и расширяя тем самым возможности поиска. С внедрением таких решений меняется традиционный подход к созданию интеллектуальных поисковых систем и систем поддержки принятия решений. Теперь появляется возможность создавать более надёжные и удобные в использовании сервисы, которые эффективно работают даже с самыми сложными пользовательскими запросами, сокращая время на поиск и повышая качество конечной информации. Кроме того, агентные поисковые модели интегрируются с несколькими версиями GPT-4 и GPT4o, что даёт гибкость выбора оптимального баланса между производительностью и ресурсными затратами. Благодаря возможности настройки максимальной длины текста, поступающего на генерацию ответа, пользователи и разработчики получают дополнительный контроль над качеством и объёмом выдаваемого контента.
Для компаний и организаций это открывает новые возможности повышения уровня обслуживания и увеличения удовлетворённости пользователей. Применение LLM для планирования запросов в RAG позволит значительно улучшить результаты, получить более точные и релевантные ответы, а также упростить процесс интеграции различных источников знаний в единую интеллектуальную систему. Текущая версия Agentic Retrieval API уже доступна для публичного использования в некоторых регионах и быстро развивается. Благодаря открытости и поддержке со стороны Microsoft, разработчики могут легко начать интеграцию и адаптацию технологии под свои нужды, используя подробную документацию и ресурсы сообщества. В итоге использование больших языковых моделей для планирования запросов в Retrieval-Augmented Generation представляет собой важный шаг вперёд в развитии систем искусственного интеллекта.
Это решение эффективно справляется с многокомпонентными и многодокументальными запросами, улучшает качество поиска и генерации, а также открывает путь к более интеллектуальным и адаптивным пользовательским интерфейсам. Такие достижения уже сегодня меняют представление о том, как должен работать современный интеллектуальный поиск, делая его более умным, быстрым и надежным.