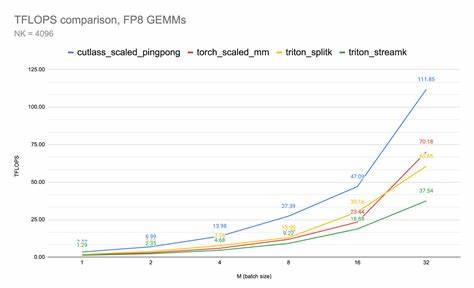
В последние годы наблюдается стремительное развитие вычислительных технологий, сопряженное с увеличением требований к производительности графических процессоров и алгоритмов машинного обучения. Одна из ключевых тенденций повышения эффективности вычислений — использование новых форматов числового представления, среди которых FP8 (числа с плавающей точкой восьмибитной точности) занимает особое место. Этот формат позволяет значительно повысить скорость операции при сохранении приемлемого уровня точности, что актуально для многих моделей глубокого обучения и обработки данных. Интересным фактом, выявленным при экспериментальных исследованиях, стало влияние имени вычислительного ядра на производительность кода, работающего с форматом FP8. В частности, когда ядро содержит слово «cutlass» в названии, наблюдается существенное увеличение пропускной способности — до 100 терафлопс.
Этот феномен связан с тем, как компилятор ptxas, который отвечает за преобразование промежуточного кода PTX в машинные команды GPU, применяет специальные аппаратные оптимизации для данного варианта именования ядра. Платформа NVIDIA GPU давно стала стандартом для ускорения задач глубокого обучения, и оптимизация работы с FP8 — часть стратегии по увеличению производительности без пропорционального роста энергозатрат и объема вычислений. Однако, в исходных реализациях софтмакс-операций и других важных математических функций на FP16 наблюдалось снижение производительности при больших контекстах из-за проблем в расписании инструкций компилятором. При этом FP8 демонстрировал более стабильные и быстрые результаты до тех пор, пока ядро не получало префикс «cutlass». Исследования показали, что внутри компилятора ptxas реализован хардкод, который проверяет имя ядра на наличие подстроки «cutlass».
Если условие выполняется, активируется особый режим оптимизации, связанный с инструкциями тензорных ядер FP8, в частности с уменьшенной мантиссой в аккумуляторе операций. Это дает возможность выполнять вычисления быстрее и эффективнее, несмотря на некоторую потерю точности, приемлемую для большинства применений в сфере искусственного интеллекта. Важным аспектом является также переход к постоянным (persistent) ядрам, что позволяет снизить время инициализации и переключений контекстов, а значит влиять на общую пропускную способность. Но именно проблема в расписании инструкций с помощью ptxas для FP16 на больших размерах контекста делает применение FP8 с оптимизацией «cutlass» предпочтительным выбором. С точки зрения практического применения, модификация имени ядра является относительно простой техникой, которая не требует кардинальных изменений в коде, но обеспечивает серьезные преимущества в скорости.
Для разработчиков и инженеров, занимающихся оптимизацией моделей машинного обучения и систем нейронных сетей, это открывает дополнительные возможности для тонкой настройки производительности. Одной из рекомендаций на текущий момент является явное добавление префикса «cutlass» к названиям ядра при работе с FP8, что гарантирует активацию ускоренной схемы компиляции. Однако, важно отметить, что такие оптимизации могут иметь экспериментальный статус и нести риск потенциальных багов из-за нестабильности. Поэтому перед применением в производственной среде необходимо тщательно провести тестирование на предмет точности и устойчивости. Дальнейшее проникновение этих знаний в сообщество разработки вычислительных ядер в сочетании с развитием поддержки новых битовых форматов FP8 на аппаратном уровне может привести к появлению еще более быстрых и оптимизированных решений для обработки больших объемов данных и обучения глубоких нейросетей.
Кроме того, накопленный опыт по работе с «cutlass»-оптимизацией поможет лучшему пониманию внутренней работы компиляторов и аппаратных ускорителей. Сегодня многие ведущие фреймворки и библиотеки глубокого обучения начинают интегрировать поддержку FP8 и рассматривают вопрос об автоматическом включении оптимизаций, основанных на имени ядра. Это может полностью изменить стандартные подходы к компромиссам между скоростью и точностью, делая машинное обучение более доступным и быстрым на массовом уровне. Также стоит обратить внимание на динамическое развитие аппаратных средств, таких как новые поколения GPU, где поддержка FP8 и связанных оптимизаций становится нативной, уменьшая роль таких «трюков» на уровне названия ядра и усиливая влияние архитектурных улучшений. Тем не менее, пока данная оптимизация существует, она представляет собой важный механизм для максимизации результатов работы с вычислениями малой точности.
В заключение, понимание и использование механизма ускорения FP8 посредством имени ядра, содержащего строку «cutlass», открывает новые горизонты для повышения производительности вычислительных задач в области искусственного интеллекта. Внимательный подход к тестированию и внедрению позволяет как профессионалам, так и исследователям извлечь максимальную пользу из доступных аппаратных и программных возможностей, что способствует общему прогрессу отрасли.





![What Every Data Scientist Needs to Know About GPUs [video]](/images/45437C7A-C44E-423A-B3D6-D5673CE51B0B)

