Pandas является одним из самых популярных инструментов для анализа и обработки данных в мире. Миллионы разработчиков и специалистов по работе с данными ежедневно используют Pandas в своих ноутбуках и проектах, чтобы проводить всевозможные операции с данными. С ростом популярности и использования Pandas стал очевиден один важный пробел — отсутствие качественного и стандартизированного бенчмарка, который позволял бы объективно оценивать производительность и возможности различных реализаций и оптимизаций API Pandas. Именно для устранения этой проблемы была создана PandasBench — первый в своём роде систематический эталонный набор тестов, ориентированный на реальные сценарии использования API Pandas в рамках однопользовательских однопроцессорных вычислений. На сегодняшний день PandasBench является крупнейшим и наиболее полноценным бенчмарком для Pandas API, включающим 102 ноутбука и свыше 3700 ячеек кода, которые собраны из реальных данных и сценариев с таких платформ, как Kaggle.
Особенностью экосистемы Python данных является огромное разнообразие задач и методов обработки данных, использующих Pandas. Например, исследования показали, что почти половина всех ноутбуков, использующих внешние библиотеки, импортируют именно Pandas. Учитывая популярность и доступность платформ, таких как Kaggle и Google Colab, можно смело утверждать, что подавляющее большинство специалистов используют Pandas именно в однопроцессорных условиях на своих локальных машинах или с ограниченными ресурсами сервиса. Это мотивация сосредоточения внимания именно на одноузловом исполнении, в отличии от распределённых систем, таких как Spark DataFrames или Snowflake. Проблема отсутствия единого бенчмарка для Pandas API выходит далеко за рамки простого неудобства.
Без стандарта оценки тяжело понять, насколько эффективно работают различные альтернативы и дополнения, на какие узкие места наталкиваются пользователи, и какие методы действительно приносят ускорение или экономию ресурсов. Предшествующие наборы тестов, ранее использовавшиеся для анализа отдельных решений, не удовлетворяли базовым требованиям к количеству, разнообразию, реальности и исполнимости входных данных и сценариев использования. PandasBench призван закрыть эту брешь благодаря тщательно собранной коллекции ноутбуков с реальными данными, а также глубокой подготовке и стандартизации среды для их воспроизведения. Сложности создания подобного бенчмарка оказались весьма существенными. Помимо выбора реальных ноутбуков, необходимо было гарантировать их работоспособность, что включало обновление устаревших вызовов API, замену deprecated методов и устранение несоответствий между кодом и данными.
Особое внимание было уделено очистке от не относящегося к Pandas кода, например обучающих моделей машинного обучения, чтобы изоляция сфокусировалась только на тестировании API Pandas. Кроме того, учитывая уникальность всех выбранных проектов и различия используемых наборов данных, применялся нестандартный подход к масштабированию данных: каждое задание масштабировалось отдельно, ориентируясь не на фиксированный коэффициент увеличения данных, а на целевое время выполнения кода. Такой подход позволил воспроизводить реальные сценарии и адекватно оценивать производительность с учётом разнообразия. На практике этот подход помог выявить ряд интересных эффектов. Например, изменение масштаба данных могло напрямую повлиять на способность различных реализаций API Pandas выполнить задачу либо привести к ошибкам из-за нехватки памяти или проблем с определением типов данных.
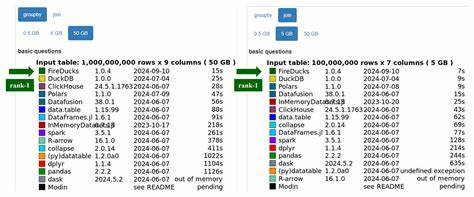
Это открытие проливает свет на то, почему некоторые «ускорители» Pandas оказываются нестабильными при варьировании размеров данных. PandasBench также позволил протестировать и сравнить основные альтернативы и дополнения API Pandas, включая Modin, Dask, Koalas и собственный инструмент Dias. Результаты оказались неутешительными для большинства систем: значительного ускорения или улучшения не наблюдалось, наибольшие возможности и покрытия были за Dias, но и он не смог ускорить большинство ноутбуков. Кроме того, многие системы столкнулись с серьёзными ограничениями по объёму потребляемой памяти, что делало их запуск невозможным на обычных компьютерах. Например, Modin в некоторых случаях достигал потребления памяти в сотни гигабайт, что выходит за рамки типичных пользовательских условий.
Другой важный результат — несовершенство покрытия API. Ни одна из протестированных систем не смогла безошибочно запустить все 102 ноутбука. Koalas и Dask справились примерно с 10, Modin — с 72, Dias — с 97. Это указывает на фундаментальные проблемы в совместимости и полноте поддержки основных вызовов Pandas, что приводит к невозможности безболезненной замены оригинальной библиотеки на альтернативы для многих реальных проектов. Анализ причин сбоев выявил широкий спектр технических проблем, начиная от ошибок типизации и неправильной обработки данных до архитектурных ограничений и особенностей внутренней реализации.
Некоторые ошибки проявлялись только после масштабирования данных, что усложняет разработку стабильных оптимизаций и требует комплексного подхода к тестированию. Таким образом, PandasBench не только выявил слабые места в существующих реализациях и оптимизациях Pandas API, но и подтвердил необходимость дальнейших исследований и разработок в этой области. Рынок и сообщество нуждаются в инструментах, которые позволят не только ускорить работу с данными, но и сохранить функциональность и стабильность в разнообразных сценариях использования. Несмотря на то, что PandasBench — это всего лишь первый шаг в развитии эталонных тестов для Pandas, создаваемый для однопроцессорных задач, он задаёт фундамент для более глубокого понимания текущего состояния инструментов. В будущем ожидается расширение бенчмарка за счёт включения распределённых облачных нагрузок и других важных классов задач, что сделает его ещё более полезным для исследователей и разработчиков.
PandasBench открывает путь для создания качественных, объективных и репрезентативных критериев оценки всех будущих оптимизаций API Pandas. Без подобной базы сложно представить себе прогресс в экосистеме аналитики данных и инструментов на базе Python. Благодаря ему исследователи способны теперь напрямую сравнивать результаты своих решений на одном и том же наборе содержательных реальных данных и задач, что повысит качество, надёжность и производительность будущих продуктов. Для инженеров и практиков, работающих с Pandas, важным станет понимание, что автоматические ускорители ещё далеки от идеала, и выбор подходящих инструментов требует взвешенного анализа конкретных задач и ограничений ресурсов. PandasBench может стать исчерпывающим источником для оценки реальной эффективности решений и выбора оптимальной стратегии работы с большими и сложными наборами данных.
В конечном итоге, PandasBench не только выявляет существующие проблемы, но и создаёт пространство для инноваций и совместного развития инструментов обработки данных. Именно такие инициативы помогают сообществу Python и аналитикам данных двигаться вперёд, улучшать экосистему и делиться общими стандартами, которые повышают качество исследований и производительности в целом.