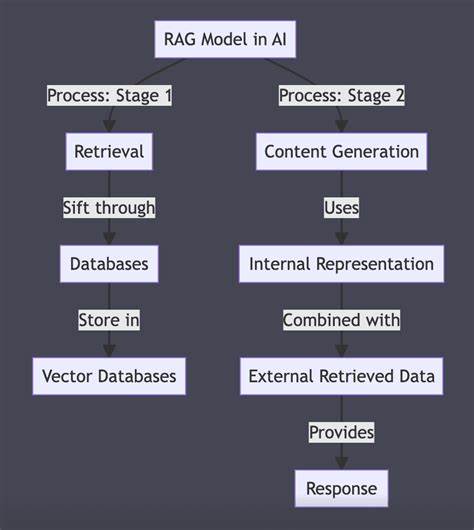
В современном мире искусственный интеллект всё активнее интегрируется в повседневную жизнь, помогая людям искать информацию, отвечать на сложные вопросы и выполнять разнообразные задачи. Одной из наиболее перспективных технологий в этой области является модель RAG, которая сочетает в себе несколько ключевых этапов для формирования максимально точного и релевантного ответа на запрос пользователя. Важно понимать, что качество ответа напрямую зависит от того, что именно видит модель прежде, чем выдаст результат. Разберёмся подробнее, что представляет собой RAG и почему правильное извлечение данных играет критическую роль. Модель RAG – это сокращение от англоязычного термина Retrieve, Augment и Generate, что можно перевести как «Извлечь», «Дополнить» и «Сгенерировать».
Эта архитектура разработана для оптимизации процесса генерации ответов с использованием внешних источников данных. Основная идея заключается в том, что сначала происходит выборка подходящей информации из базы документов или коллекции текстов (Retrieve), затем извлечённые данные используются для обогащения первоначального запроса (Augment), и уже на базе расширенного контекста формируется окончательный ответ (Generate). Первый этап – извлечение – является основополагающим для успеха всей системы. Если выбранный контекст некорректен, неполон или нерелевантен, то плохое качество данных передаст свои ошибки и следующему этапу. В таких случаях даже самый продвинутый генератор текста не сможет создать адекватный ответ, поскольку опирается на недостоверные или искажённые сведения.
Предположим, что пользователь запрашивает информацию по узкой теме из научной области, но алгоритм извлечения выбирает устаревшие статьи или документы с неполным описанием. В результате полученный ответ будет ошибочным либо неполным, что вызовет разочарование и недоверие. Второй этап – дополнение запроса – служит для интеграции выбранных данных непосредственно в промпт, который затем подается модели генерации. Такой приём увеличивает осведомленность ИИ об актуальном контенте и помогает ему сформировать связный и информативный ответ, опираясь одновременно на собственные знания и извлечённые материалы. Важной особенностью здесь является необходимость точного и релевантного соответствия между исходным вопросом и добавляемой информацией, чтобы избежать путаницы и ненужного усложнения запроса.
Затем наступает заключительный этап генерации, где модель формирует ответ, используя расширенный контекст. В ходе этого этапа ИИ проводит слияние всех доступных данных и Генерирует текст, отвечающий на запрос. Эффективность результата зависит от предыдущих этапов, а также от внутренней архитектуры самой генеративной модели. Без качественного извлечения и дополнения ответ будет поверхностным или ошибочным, даже при использовании передовых языковых моделей. Кроме того, важно отметить роль пользовательского интерфейса и дополнительных инструментов, которые помогают понять, что именно «видит» модель.
Платформы и приложения, как RAGsplain, предоставляют возможность загружать различные форматы – короткие видео, аудио или текстовые документы – чтобы проанализировать, как именно модель извлекает и обрабатывает информацию. Это не только повышает прозрачность ИИ, но и позволяет обнаруживать узкие места и оптимизировать процесс работы с контекстом. Проблема, с которой часто сталкиваются разработчики и пользователи моделей RAG, — это качество исходного материала. От выбора источников данных, их актуальности и полноты зависит конечная точность. Иногда сам пользователь перегружает систему нерелевантной информацией или слишком узким контекстом, что снижает общую эффективность.
В таких ситуациях зачастую помогает ручная доработка вызова или включение дополнительных этапов фильтрации и классификации документов перед их передачей на этап генерации. Использование RAG в различных областях уже показало большую эффективность. В образовательных проектах система помогает находить точные определения и объяснения сложных терминов. В бизнес-анализе RAG ускоряет поиск нужной документации и автоматизирует ответы на часто задаваемые вопросы клиентов. В научных исследованиях технология позволяет быстро обрабатывать большие базы данных и извлекать релевантные исследования, что существенно экономит время исследователей.
Несмотря на перспективность, RAG модели всё еще находятся в стадии активного развития. Вызовы, связанные с корректной сортировкой и обработкой больших объёмов информации, а также комплексностью интеграции с внешними источниками, требуют постоянного совершенствования. Многие компании и исследовательские группы экспериментируют с новыми алгоритмами извлечения и усиления, внедряют улучшенные методы обучения языковых моделей на специализированных наборах данных. В будущем можно ожидать более тесной интеграции RAG с мультимодальными системами, способными одновременно анализировать текст, аудио и видео, что существенно расширит возможности искусственного интеллекта. Более продвинутые механизмы внимания и фильтрации позволят ещё лучше выбирать контекст и обеспечивать глубокое понимание пользовательских запросов.
Это откроет новые горизонты как для разработчиков, так и для конечных пользователей, которые ежедневно сталкиваются с необходимостью обрабатывать большой поток информации. В итоге, понимание того, что именно «видит» RAG модель перед генерацией ответа, имеет решающее значение для создания эффективных и надёжных систем искусственного интеллекта. Качество извлечения и дополнения информации напрямую влияет на точность, развернутость и полезность ответа. Поэтому правильный выбор источников, актуализация данных и тщательная работа над этапами обработки становятся ключевыми факторами успеха.