В мире исторических компьютеров Commodore PET и его BASIC занимают особое место как одни из первых массово доступных вычислительных платформ. Несмотря на то, что их программирование выглядит на первый взгляд достаточно простым, за этим простым фасадом скрывается масса тонкостей, связанных с обработкой кода и особенностями самой среды BASIC. Одной из таких особенностей является токенизация — процесс преобразования текста программы в внутреннее компактное представление. Особый интерес представляет традиционная ошибка, известная как "LET HEN", которая происходит в ранних версиях Commodore BASIC 1.0 и связана именно с принципами токенизации и парсинга кода.
Токенизация — это механизм, лежащий в основе интерпретации программ BASIC на Commodore PET. Из-за ограниченных ресурсов процессоров и памяти в начале 80-х годов, для хранения и выполнения программ использовался компактный формат. При вводе программы она разбирается на элементы — ключевые слова, операторы и переменные. Вместо хранения каждого ключевого слова в виде текста, BASIC заменяет их на специальные коды, токены, которые занимают меньше места и позволяют быстрее обрабатывать команды. При этом любой текст, который не распознан как ключевое слово, сохраняется как обычный ASCII-текст — переменные, константы и прочее.
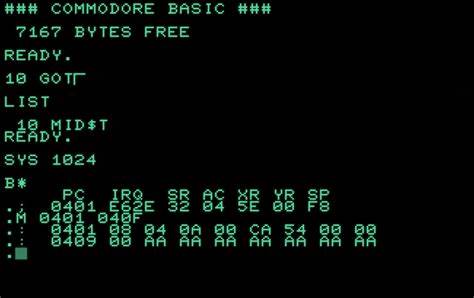
Отсутствие обязательных пробелов между ключевыми словами и идентификаторами в BASIC, в принципе, облегчало набор команд с клавиатуры, однако усложняло процесс распознавания и токенизации программного кода. В BASIC не требовалось ставить пробелы между командами и идентификаторами. Например, две строки: «FOR I=0 TO 10 STEP 2» и «FORI=0TO10STEP2» работали одинаково, хотя первая более читаемая для человека, а вторая — более экономная по памяти и чуть быстрее. Именно такая особенность породила ошибку, известную как «LET HEN». В версии 1.
0 BASIC на Commodore PET следующая строка вызовет сбой: 10 IF LS = LE THEN GOTO 100 Эта строка, на первый взгляд, корректна, однако при вводе и последующем листинге становится заметно, что в выводе отсутствует пробел между "LE" и "THEN" — получается «LETHEN», а интерпретатор воспринимает это как ключевое слово «LET» и оставшуюся часть «HEN» как непонятное выражение, выдавая синтаксическую ошибку. Это свидетельствует о том, что токенизатор в версии 1.0 пропускает пробелы в ключевых словах, в то время как для остальных частей программы пробелы сохраняются. Причина такого поведения кроется в подходе раннего BASIC к интерпретации. В отличие от большинства современных языков, BASIC эпохи PET рассматривал пробелы как необязательные в токенах с ключевыми словами.
То есть, ключевые слова могли быть прочитаны без обязательных пробелов, а комбинация символов анализировалась как одно целое. Таким образом, последовательность букв, образующая цепочку символов, находящуюся рядом без пробелов, потенциально могла быть разобрана как ключевое слово с добавлением следующей буквы, если она стоит сразу за ним. Процесс токенизации происходил за счёт обхода строкового буфера, символ за символом сравнивая поступающий текст с известным списком ключевых слов. Этот список представлял собой набор слов с метками, указывающими конец каждого слова, обозначенный установкой старшего (знакового) бита в коде символа, что позволяло быстро определять окончание слова. При совпадении токен заменялся на один байт - уникальный код команды, что экономило память и ускоряло интерпретацию.
Остальной текст — идентификаторы, числа, операторы — копировался как есть. Однако этот жесткий метод проверки порождал неоднозначности при отсутствии пробелов. Например, уменьшение «LE THEN» до «LETHEN» с точкой разрыва внутри приводит к тому, что система воспринимает начало «LET» как ключевое слово, игнорируя пропущенный пробел, а остаток строки уже не может быть корректно распознан. Далее в развитии BASIC была устранена эта особенность. В более поздних версиях, начиная с BASIC 2.
0 (“New ROM”), такие ошибки устранены тем, что пробелы в ключевых словах не пропускались во время анализа. В результате прежняя странность исчезла, и оператор «LET HEN» перестал восприниматься как ключевое слово «LET» с остатком «HEN», а был обработан как отдельные слова благодаря обязательному требованию разделения пробелов. Кроме того, нововведения в BASIC 2.0 включали введение специального ключевого слова «GO» как дополнение к существующему «GOTO», для сохранения поддержки двухсловных операторов, таких как «GO TO». Это было как бы компромиссное решение, намеренно добавленное, чтобы не нарушить сложившиеся текстовые конструкции, используемые программистами, поскольку полное исключение игнорирования пробелов могло привести к несовместимости с ранее написанными программами.
Интересна также в этом контексте особенность интерпретатора с обработкой числовых констант, например, записи чисел с пробелами «1 000 000 .00». Несмотря на то, что при листинге пробелы сохраняются, интерпретатор, когда дело доходит до выполнения, игнорирует эти пробелы, объединяя число в одно целое. Это демонстрирует, что интерпретатор старался сохранять удобочитаемость программ для пользователя, даже если это влияло на скорость выполнения и объем кода в памяти. Токенизатор работал с входным буфером BASIC, который в версии 1.
0 размещался в самом низу памяти (за пределами нулевой страницы), что влияло на организацию кода и скорость доступа. Во время обработки каждая введённая строка разбиралась на токены и сохранялась в виде связного списка, где каждая строка знала адрес следующей. Это облегчало вставку, удаление и поиск строк по номеру. Сам алгоритм токенизации включал итеративный проход по символам, особую обработку кавычек (учет строковых констант), комментариев (REM), и ключевых слов с игнорированием пробелов внутри них. В случае совпадения с ключевым словом происходила замена ASCII-последовательности на один байт-токен, в противном случае символ сохранялся без изменений.
Нельзя не упомянуть и о найденной ошибке — "баге" токенизатора, связанной с обработкой символов с установленным знаковым битом (как в PETSCII). При определенных условиях происходит так называемый «run-away» эффект, когда токенизатор неправильно интерпретирует последовательность ключевых слов, смещая счетчик и создавая неверный токен. Это может привести к неожиданным изменениям исходного кода и синтактическим ошибкам. Интересно, что разные версии BASIC вносили свои изменения в механизм токенизации. Например, Sinclair BASIC полностью передавал токенизацию пользователю через код клавишных комбинаций, что значительно ускоряло проверку синтаксиса и выполнение, но требовало других привычек у программиста.
В то время как MS BASIC, лежащий в основе Commodore, ориентировался на последовательный поток символов, поступающий из терминала, и его токенизатор был более универсальным, но менее оптимальным. Дальнейшие версии BASIC, такие как Commodore BASIC 4.0, расширяли функциональность языка, включая новые команды для дисковой подсистемы и улучшенный редактор, но при этом сохранили суть работы токенизатора, лишь оптимизируя загрузку и обработку ключевых слов. Особый интерес для исследователей представляет сравнение реализации токенизатора на уровне ассемблерного кода. Внимательный анализ показывает элегантность и одновременно компромиссное решение разработчиков, балансировавших между размером заливки ROM, скоростью работы и удобством пользователя.
В частности, сохранение оригинального текста для листинга и возможности редактирования требовало делать токенизацию обратно преобразуемой и эффективной. Таким образом, изучение ошибки «LET HEN» и общая архитектура токенизатора в Commodore BASIC — это не просто воспоминание о технической истории, но и урок проектирования в условиях ограниченных ресурсов. Это показывает, как ранние компьютерные системы решали сложные задачи распознавания и интерпретации кода, что было фундаментом для развития более современных средств программирования. Для любителей ретро и программистов, интересующихся эволюцией языков программирования, понимание этих процессов позволяет лучше ознакомиться с историей информатики и оценить сложности, с которыми сталкивались пионеры вычислительной техники. А также понять, почему так важны пробелы и форматирование в языке BASIC — и как незначительная оплошность в токенизаторе может привести к загадочным ошибкам и неожиданному поведению программы.
В заключение, токенизация Commodore BASIC на PET — пример того, как аппаратные ограничения и совместимость с традициями влияли на развитие языков программирования. Если вы хотите освоить или эмулировать работу старых компьютеров, понимание этих особенностей поможет эффективнее работать с кодом и избегать типичных ловушек, а также погрузиться в атмосферу эпохи ранних персональных вычислений.

![Cycling in London: a personal look at safety, cost, and mental health [video]](/images/A2664212-33EF-48C3-B0CF-7CC05CD83538)