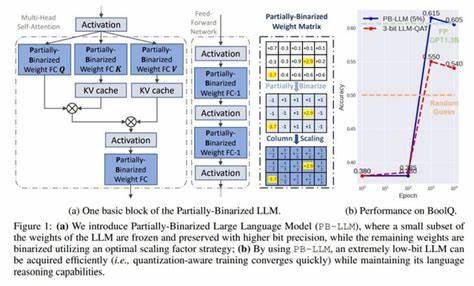
Разработка ядра Linux всегда была сложным, масштабным и трудоемким процессом, требующим глубоких знаний и высокого уровня экспертности. В последние годы появились новые технологии, способные оказать существенную помощь разработчикам ядра, среди которых крупные языковые модели (LLM, Large Language Models) занимают особое место. Эти модели основаны на машинном обучении и умеют обрабатывать, интерпретировать и генерировать тексты на естественном языке, что открывает двери для их использования в различных этапах разработки и поддержки ядра Linux. Крупные языковые модели представляют собой сложные алгоритмы, способные анализировать огромные объемы текста и выявлять закономерности. В отличие от традиционных детерминированных инструментов разработки, LLM действуют вероятностно, подбирая наиболее вероятное продолжение текста или кода на основе контекста.
При этом модели обучаются на обширном корпусе данных, что позволяет им ориентироваться в сложной терминологии и сложных концептах, характерных для разработки ядра. Одним из главных преимуществ LLM является возможность обработки больших объемов информации в пределах так называемого «окна контекста». Современные модели могут “держать в памяти” сотни тысяч токенов — этого достаточно, чтобы охватить целый подсистемный модуль ядра и много связанных с ним данных. Это позволяет эффективно осуществлять поиск, анализ и генерацию кода с учетом контекста, что значительно облегчает работу разработчика. Применение LLM в ядре Linux уже принесло конкретные результаты.
В некоторых случаях модели успешно генерировали патчи, которые затем прошли проверку и были включены в релиз ядра. Такие исправления обычно касаются небольших и четко очерченных задач, например, корректировки параметров, оптимизаций или обновления API. Кроме того, LLM помогают создавать качественные сообщения коммитов, которые зачастую оказываются сложнее, чем сам код — особенно это актуально для разработчиков, для которых английский язык не является родным. Примером принятого патча, полностью сгенерированного LLM, является исправление, связанное с обновлением размера хеш-таблицы с числового значения к степеням двойки, что соответствует новым требованиям API ядра. Модель не только учла необходимость использовать степень двойки, но и оптимизировала код, удалив избыточные операции.
Такие примеры демонстрируют, что LLM способны создавать не только работоспособный, но и эффективный код. Еще один случай успешного применения LLM — создание скрипта git-resolve, призванного разрешать неоднозначные или частично неверные идентификаторы коммитов. Помимо корректной работы, скрипт содержит набор автотестов и документацию, что нетипично для скриптов, поддерживаемых в ядре, но показывают, насколько комплексным и детальным может быть результат сотрудничества разработчика и LLM. Одно из ключевых направлений применения LLM — поиск и категоризация исправлений, относящихся к безопасности и устойчивости. Обработка и отбор патчей для их бэкапорта в стабильные ветки ядра — обычная рутинная задача с большими трудозатратами, ведь ежедневно приходится рассматривать сотни изменений.
Здесь инструмент AUTOSEL с поддержкой LLM стал незаменимым помощником. Он анализирует историю коммитов, создает векторные представления каждого изменения (эмбеддинги), и на основе семантического сходства предлагает наиболее подходящие патчи для бэкапорта. Использование технологии Retrieval Augmented Generation (RAG) помогает LLM избегать ошибок и «галлюцинаций», когда модель придумывает несуществующие функции или детали. RAG позволяет модели обращаться к реальной базе знаний, включая git-репозитории с историей ядра и документацией, тем самым обеспечивая обоснованность и прозрачность рекомендаций. Альянс человеческого опыта и технологий открывает новые горизонты.
Разработчики все еще проводят ресърч и верификацию кода, однако с помощью LLM повышение продуктивности и снижение числа пропущенных важных исправлений становится возможным. Периодическая оценка качества инструментов на практике демонстрирует высокую точность и надежность, снижая утомляемость и повышая качество поддержки стабильных веток. Тем не менее интеграция LLM в процесс разработки вызывает ряд вопросов, выходящих за рамки технической реализации. При использовании автоматически сгенерированного кода встает тема авторства и ответственности. По условиям лицензирования Linux и требований Developer's Certificate of Origin (DCO), автор обязательно должен подтверждать право на распространение изменений.
Однако право собственности на такие изменения, созданные искусственным интеллектом, пока не до конца урегулировано в юридическом поле. Отсутствие четкой позиции по вопросам интеллектуальной собственности затрудняет формализацию вклада LLM. Комьюнити ядра Linux ведет активный диалог по вопросам прозрачности: стоит ли указывать, что патч был создан с применением ИИ, и как это отразится на доверии и ответственности? На практике многие разработчики воспринимают LLM как мощный инструмент — аналог современных автоматизированных систем, таких как статические анализаторы и генераторы патчей, которые не нуждаются в отдельном упоминании, пока их результаты проходят полноценную валидацию. Также обсуждается возможное влияние на качество и природу программирования. Опасения связаны с тем, что чрезмерное полагание на ИИ-инструменты может привести к снижению роста новых экспертов и обзоров, поскольку разработчики могут утрачивать глубокое понимание кода, переданного на аутсорсинг моделям.
Для поддержания высокого уровня качества важно сохранить баланс между автоматизацией и развитием человеческих навыков. Вопросы энергопотребления и экологической устойчивости моделей также имеют значение. Обучение и эксплуатация крупномасштабных языковых моделей требуют значительных ресурсов. Однако рост производительности и потенциал экономии времени разработчиков может со временем компенсировать эти издержки. Дополнительные исследования в этой области обещают сделать применение LLM экологически более приемлемым.
В перспективе можно ожидать, что технологии на базе LLM будут расширять свои функции, охватывая автоматическое обнаружение дефектов в патчах еще до их принятия, сложный анализ безопасности и помощь в обучении новых членов сообщества. По мере снижения стоимости вычислений и увеличения доступности мощных моделей эти задачи станут реализуемыми в повседневной работе ядра. Таким образом, крупные языковые модели открывают новую эру в открытом развитии ядра Linux. Они не заменяют человека, но становятся его надежным соратником в борьбе с рутинными, многообъемными и сложными задачами, позволяя ученым и инженерам сосредоточиться на творческом и стратегическом развитии ядра. Важна ответственность и прозрачность при использовании таких инструментов, а также продолжение обсуждений по лицензированию и юридическим аспектам, что обеспечит здоровое и эффективное будущее разработки.
Применение LLM в разработке ядра — это не история о том, как машина заменит человека, а скорее об умном сотрудничестве, где каждый участник, включая искусственный интеллект, приносит свой ценный вклад. Как и с каждым новым технологическим шагом, в этой области предстоит решить множество задач, но уже сегодня видно, что синергия человека и ИИ может вывести сообщество Linux на качественно новый уровень развития и надежности.