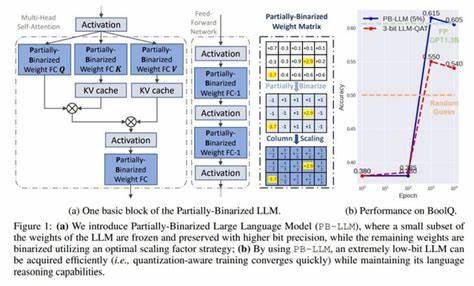
Большие языковые модели (БЯМ) произвели настоящую революцию в области обработки естественного языка, позволив создавать системы, способные генерировать связный и содержательный текст, понимать контекст и выполнять широкий спектр задач от перевода до анализа тональности. При этом огромный объем данных и миллиарды параметров требуют значительных ресурсов памяти и вычислительной мощности, что создает серьезные препятствия для их развертывания и эффективного использования, особенно на мобильных и встроенных устройствах. В связи с этим ученые и инженеры постоянно ищут методы сжатия и оптимизации моделей, позволяющие сохранить уровень их производительности при значительно меньших затратах на оборудование и энергию.Одним из наиболее перспективных направлений является квантование весов моделей — процесс представления значений параметров с помощью более компактных числовых форматов, заменяющих традиционные 32-битные числа на низкоразрядные аналоги. Несмотря на существующие успешные практики в 8-битном квантовании, дальнейшее снижение до экстремально низких разрядов, например 2 или 3 бит на вес, сталкивается с серьезными трудностями, связанными с потерей точности и ухудшением качества генерации текста.
В этой области недавно представлен инновационный подход под названием LCD (Low-bit Clustering via Knowledge Distillation), который объединяет кластеризацию и дистилляцию знаний для эффективного квантования с минимальными потерями.Основная идея LCD заключается в использовании кластеризации для группировки весов модели с последующим присвоением им ограниченного набора значений, что позволяет добиться компактного представления. В отличие от традиционных методов с равномерным распределением квантов, кластеризация адаптируется под структуру данных модели, обеспечивая более точное приближение и сохранение значимых особенностей параметров. Чтобы избежать деградации качества при экстремальных степенях сжатия, используется дистилляция знаний — метод обучения модели с низкоразрядным представлением через подражание выходам и внутренним представлениям более крупного и точного учителя. Такой метод обеспечивает передачу накопленных знаний без необходимости повторного обучения на огромных объемах данных, что значительно ускоряет процесс оптимизации и повышает стабильность результатов.
LCD применяет тщательно продуманные техники оптимизации, позволяющие сохранять эффективность моделей на уровне, близком к исходным, даже при использовании всего 2-3 бит на вес. Помимо сжатия параметров, метод включает компрессию активаций с помощью сглаживания, что дополнительно снижает затраты памяти во время инференса и повышает общую скорость работы. Особое внимание уделяется реализации через Lookup Table (LUT) — таблицу соответствия, позволяющую ускорить вычисления и свести сложные операции к простым обращениям к памяти, что в реальных сценариях приводит к значительному увеличению производительности.Экспериментальные результаты проекта LCD впечатляют — демонстрируется превосходство над существующими методами в сочетании высокой точности и быстродействия. В частности, достигается ускорение инференса в несколько раз по сравнению с исходными моделями и традиционными подходами к квантованию.
Это открывает новые возможности для интеграции БЯМ в мобильные приложения, интернет вещей, и другие ресурсоограниченные среды, значительно расширяя спектр практического применения передовых технологий ИИ. Важным аспектом является и экономическая эффективность — оптимизации снижают потребность в дорогостоящем оборудовании и упаковке, делая технологии более доступными для стартапов, научных лабораторий и промышленных компаний.Кроме того, LCD способствует снижению энергопотребления, что актуально не только с точки зрения финансов, но и с экологической позиции. Создание «зеленых» и энергоэффективных моделей является трендом мирового уровня и соответствует задачам устойчивого развития современного цифрового общества. Методы квантования с дистилляцией становятся ключевыми для долгосрочной интеграции ИИ в повседневную жизнь, обеспечивая баланс между мощностью и ответственным использованием ресурсов.
Реализация LCD требует внимательного подхода к архитектуре моделей, продвинутым алгоритмам обучения и инструментам автоматизации. Платформы машинного обучения и фреймворки уже начинают включать поддержку низкоразрядного квантования и знания дистилляции, что упрощает внедрение новых методик в практическую деятельность. Исследователи продолжают развивать идею, расширяя возможности LCD и комбинируя её с другими методами оптимизации, такими как праунинг весов и динамическое распределение ресурсов.Таким образом, экстремальное низкоразрядное квантование с кластеризацией и дистилляцией знаний является прорывным решением для масштабируемого и эффективного использования больших языковых моделей. Оно помогает преодолеть существующие барьеры производительности и ресурсов, делая технологии искусственного интеллекта более универсальными, доступными и экологичными.
В ближайшем будущем благодаря таким инновациям можно ожидать появления ещё более компактных и быстрых моделей, которые смогут интегрироваться в самые разные устройства и приложения, меняя представление о возможностях ИИ и открывая новые горизонты для науки, бизнеса и общества.



![A Poor Man's User Study with a Vision Model and E[P]](/images/529E854D-4355-4E86-96CA-1B4495F9B0DE)