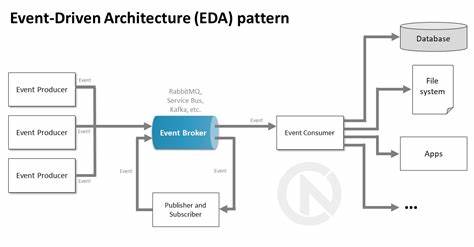
Архитектура, основанная на событиях, или event-driven architecture (EDA), продолжает набирать популярность среди разработчиков и архитекторов программных систем благодаря своей способности обеспечивать гибкость, масштабируемость и устойчивость приложений. Однако ключ к успешному применению этой архитектуры заключается не столько в выборе конкретных технологий, сколько в правильном проектировании событий — основных строительных блоков EDA. Неверно спроектированные события способны превратить систему в сложный, плохо управляемый монолит, где изменения приводят к каскадным ошибкам, а отладка становится настоящей головоломкой. Важно разобраться в лучших паттернах проектирования событий, которые позволят создавать системы с неожиданно высокой надежностью и простотой сопровождения. В этой статье мы подробно рассмотрим назначение и особенности основных паттернов проектирования событий и раскроем их преимущества и недостатки применительно к современным технологиям, включая облачные сервисы AWS.
Ключевая задача любой event-driven архитектуры — сделать события понятными, лаконичными и автономными. Каждое событие представляет собой соглашение между сервисом-издателем и его потребителями. Если событие содержит недостаточно данных, потребители вынуждены делать дополнительные запросы к API, увеличивая время отклика и создавая дополнительную нагрузку. Если в событии излишне много данных, появляется риск нарушения границ ответственности сервисов, ухудшается производительность, появляются проблемы с безопасностью и сложностью изменения схемы данных. Всем этим можно избежать, если применять соответствующие паттерны проектирования событий, тщательно продумывая их содержание и структуру.
Одной из самых распространенных ошибок является так называемый паттерн "Толстых событий" (Fat Events). В этом подходе события включают в себя данные, которые сервис-издатель прямо не владеет и не контролирует. Например, служба заказов публикует событие с информацией о заказе, но также включает кредитный рейтинг клиента, текущий уровень лояльности и состояние запасов на складе. Данные о клиенте или товарных запасах принадлежат другим сервисам, и их включение нарушает доменные границы. Помимо нарушения принципов областей ответственности, такие события становятся источником сильной связности между микросервисами, что приводит к необходимости синхронизированных изменений и потенциальным ошибкам.
Кроме того, данные в толстых событиях быстро устаревают, поскольку сервис-заказчик не гарантирует актуальность внешней информации при публикации. Это создает нестыковки в системе и ставит под угрозу целостность бизнес-логики. С точки зрения безопасности и комплаенса, подобные события могут открывать доступ к конфиденциальной информации для неавторизованных потребителей. Все эти негативные последствия можно избежать, если в события включать только те данные, которыми сервис действительно владеет, а для остальных использовать идентификаторы или ссылки на источник, где потребители смогут при необходимости получить актуальную информацию. Одним из основных паттернов является Event Carried State Transfer (ECST), при котором события содержат часть состояния, необходимого для работы потребителей.
ECST можно разделить на два подхода. Первый — полный снимок сущности (Full Entity State), когда событие содержит все текущее состояние объекта. Например, событие Customer Updated будет иметь полный профиль клиента со всеми подробностями, включая адреса, подписки и метаданные. Такой метод позволяет каждому потребителю построить или обновить локальное представление объекта без необходимости делать запросы к сервису-источнику. Он часто применяется в системах аналитики, биллинга и маркетинга, где разные потребители нуждаются в различных срезах данных, и это помогает уменьшить зависимость и повысить производительность.
Однако у этого подхода есть свои недостатки. Во-первых, события могут иметь огромный размер (до 50 КБ и более), что повышает требования к пропускной способности и хранению данных. Во-вторых, из-за большого объема не всегда целевой потребитель нуждается во всех данных, что увеличивает риски утечки чувствительной информации и усложняет внедрение изменений в схему данных, поскольку любое изменение требует координации между всеми потребителями. Второй подход — контекстное состояние (Contextual State), когда событие содержит только ту информацию, которая непосредственно необходима для понимания и обработки событийного процесса. Например, событие Order Submitted будет содержать данные о заказе, платежах и доставке, но без деталей о предпочтениях клиента или истории активности.
Такой подход оптимален для процессов с четко определенными бизнес-правилами и высокими требованиями к производительности, позволяя уменьшать размер сообщений (до нескольких килобайт) и ограничивать распространение данных. К недостаткам контекстного состояния относится сложность в правильном определении набора необходимых данных для каждого потребителя, что требует глубокого анализа бизнес-процессов. Есть риск оставить в событиях избыточные данные "на всякий случай", приводя к постепенному увеличению связности и усложнению архитектуры. Также если прогнозы не оправдались, потребители вынуждены выполнять дополнительные запросы к сервисам, что снижает эффективность. На платформе AWS для реализации ECST зачастую выбирают комбинацию из EventBridge и SQS.
EventBridge отвечает за интеллектуальную маршрутизацию и фильтрацию событий, а SQS гарантирует надежную доставку сообщений отдельным потребителям. В высоконагруженных системах с требованиями к аналитическому потоку используют Amazon Kinesis Data Streams, который поддерживает потоковую обработку с высокой пропускной способностью и обеспечивает возможность повторного воспроизведения событий. Другой популярный паттерн — Event Notification, при котором события содержат только минимальную информацию для уведомления о наступлении факта изменений без детального состояния. Потребители в ответ делают запросы к API, если необходимы подробные данные. Такой подход хорошо подходит для сценариев с большим числом разнообразных потребителей, при ограничениях по пропускной способности и безопасности.
Например, финансовая система может публиковать уведомления о изменениях состояния счета без передачи конфиденциальных данных баланса, и аудиторские сервисы или службы комплаенса смогут запрашивать актуальную информацию по необходимости. Минусы этого подхода связаны с повышенной сложностью работы потребителей, которые должны самостоятельно реализовывать логику обращения к API, что ведет к увеличению задержек и сложности поддержки. Кроме того, существует риск рассинхронизации данных в момент между уведомлением и фактическим запросом, а также появляется зависимость между потребителями и сервисом-источником, что снижает гибкость системы. На AWS для Event Notification часто выбирают EventBridge из-за его развитых возможностей маршрутизации и управления схемами, а для массовых рассылок может использоваться Amazon SNS, которая отлично масштабируется и поддерживает разные протоколы доставки, включая SMS и email. Паттерн асинхронных команд (Async Commands) отличается от событий тем, что представляет собой запросы на выполнение действий, а не описание прошедших изменений.
Команды размещаются в очередях, после чего специализированные обработчики получают их и выполняют необходимые операции, подтверждая успешное выполнение через отдельные события. Этот подход важен при построении оркестрации бизнес-процессов, обеспечении надежности и повторного выполнения задач. Асинхронные команды создают более жесткую связь между отправителем команды и обработчиком, требуют построения надежной инфраструктуры обработки ошибок и поддержку порядка выполнения команд, но при этом позволяют разгрузить пользовательские интерфейсы и повысить отзывчивость системы. Для реализации на AWS используют Amazon SQS с поддержкой FIFO-очередей для гарантии порядка обработки и встроенными механизмами повторной попытки и Dead Letter Queue для обработки неудачных запросов. Паттерн Change Data Capture (CDC) нацелен на извлечение изменений из баз данных и трансформацию их в события, что особенно полезно при интеграции с унаследованными системами или когда приложения строятся вокруг базы данных.
CDC позволяет минимизировать изменения в существующих приложениях, обеспечивая при этом синхронизацию и актуальность данных в других сервисах. Например, изменение email клиента в базе данных приведет к публикации события с деталями изменения, которое затем обрабатывают аналитические или поисковые сервисы. Среди сложностей CDC стоит выделить нагрузку на downstream-системы от большого потока изменений, недостаток бизнес-контекста в событиях и сложность управления безопасностью данных на уровне баз. Также требуется инфраструктура по трансформации и маршрутизации этих событий. AWS предлагает для CDC разные инструменты — для DynamoDB это DynamoDB Streams с рестриктом по времени хранения и размеру записи, для реляционных баз — AWS Database Migration Service, которая поддерживает множество СУБД и позволяет работать как в режиме выгрузки, так и реального захвата изменений.
Для масштабных сценариев используется Amazon Kinesis Data Streams, который аккумулирует и распределяет CDC-события. Выбор подходящего паттерна сильно зависит от требований к данным, производительности, уровню связности и навыкам команды. В реальных системах часто сочетаются разные паттерны, оптимально распределяя нагрузку и упрощая интеграцию. Правильно спроектированное событие — это ясный рассказ о бизнес-событии, который позволяет понять логику работы без погружения в детали реализации. Именно такое проектирование событий создает фундамент, на котором строится поддерживаемая, расширяемая и эффективная event-driven архитектура.
В конечном итоге цель — не следовать шаблонам слепо, а создавать события, которые облегчают жизнь разработчикам и оператором, делают систему прозрачной и предсказуемой. Когда ночью в продакшене возникает сложная ситуация, возможность быстро разобраться, читая события и понимая по ним цепочку бизнес-действий, является золотым стандартом качества любой распределённой архитектуры на основе событий.