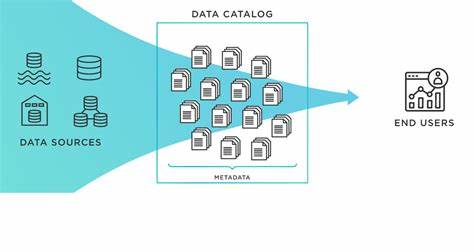
В современном мире объемы данных стремительно растут, и организации сталкиваются с вызовами хранения, управления и анализа информации из множества источников. Традиционные решения часто требуют развертывания серверов, баз данных и обслуживания сложных распределенных систем, что увеличивает затраты и усложняет рабочие процессы. В этом контексте появляется datarepo — платформа, которая предлагает уникальный подход к созданию и использованию каталогов данных без необходимости запуска каких-либо сервисов или баз данных. Основная идея datarepo заключается в предоставлении простой, но мощной системы для описания, поиска и запроса данных из разнообразных источников с помощью декларативного синтаксиса на Python. Это дает возможность разработчикам и аналитикам легко описывать каталоги, базы данных и таблицы, связывать их с реальными хранилищами данных, такими как Delta Lake, Parquet и реляционные базы, а также создавать кастомные таблицы через Python-функции.
Одной из главных особенностей платформы является ее универсальность и масштабируемость. Datarepo способна работать как на локальном уровне — на ноутбуке разработчика, так и на масштабируемых кластерах без необходимости развертывания сложной серверной инфраструктуры. Это делает инструмент крайне удобным как для прототипирования и разработки, так и для промышленного использования. Важным моментом является то, что datarepo строится на высокопроизводительных Rust-библиотеках, таких как polars, delta-rs и Apache DataFusion. Использование этих технологий обеспечивает быструю и эффективную работу с большими объемами данных, что особенно важно в условиях современных аналитических нагрузок.
Процесс работы с datarepo начинается с описания таблиц и каталогов с помощью Python. Это описание включает схему данных, URI — адреса хранилища, фильтры и метаданные. Такой подход, называемый «код как каталог», позволяет хранить конфигурацию каталогов в виде кода, что упрощает версионирование, рефакторинг и совместную работу. Пример использования datarepo иллюстрирует создание таблиц, например, Delta Lake или Parquet, с указанием их схемы и фильтров, а также функций, которые возвращают данные в формате LazyFrame через polars. Эти таблицы затем объединяются в базы данных и каталоги, которыми можно управлять программно.
Таким образом, пользователи могут выполнять сложные запросы, объединять таблицы из разных источников и работать с агрегированными данными. Отдельное внимание заслуживает возможность генерации статического сайта такого каталога. После описания каталога, datarepo позволяет с помощью одной команды экспортировать его в статический сайт, который можно развернуть для визуального обозрения всех доступных данных. Такой сайт служит в качестве документированной справочной системы для команды, упрощая обмен знаниями и ускоряя доступ к данным. Кроме статического сайта, datarepo поддерживает автоматическую генерацию конфигурационных файлов для ROAPI — системы для быстрого построения API на основе YAML.
Это открывает дополнительные возможности для предоставления данных в виде удобных для интеграции API без необходимости писать дополнительный серверный код. Философия datarepo сводится к упрощению задач инженерии данных через отказ от сложных распределенных систем в пользу легковесных, модульных решений. Платформа нацелена на обеспечение масштабируемости при минимальных накладных расходах и максимальной гибкости для разработчиков. Еще одним преимуществом datarepo является открытость и связь с сообществом. Проект поддерживается Neuralink и доступен как open source, что позволяет сообществу вносить вклад, расширять функциональность и использовать инструмент без дополнительных затрат.
Для разработчиков и компаний, стремящихся повысить эффективность работы с данными, datarepo предлагает новые возможности, позволяя упрощать архитектуру, ускорять доступ к данным и снижать затраты на инфраструктуру. Благодаря унификации интерфейса к различным источникам и декларативному описанию каталогов, работа с данными становится более прозрачной и предсказуемой. В заключение стоит отметить, что datarepo меняет взгляд на организацию данных, выводя процесс управления из-под контроля серверных сервисов и баз данных и интегрируя его глубже в среду разработки через код. Такая парадигма открывает перспективы для инноваций и упрощения многих аспектов работы с данными в условиях быстро меняющихся требований современного бизнеса.