В последние годы развитие алгоритмов генерации изображений и нейросетевых моделей набирает стремительные обороты. Одним из наиболее заметных и многообещающих направлений является оптимизация моделей диффузии, таких как Flux, которые демонстрируют впечатляющие результаты в генерации визуального контента. В то время как вычислительные мощности становятся все более доступными, эффективное использование ресурсов, особенно мощных графических процессоров нового поколения, становится ключом к достижению максимальной производительности и экономии времени. Архитектура NVIDIA Hopper и графические процессоры H100 в частности предоставляют огромное количество вычислительных ресурсов, однако, чтобы раскрыть их весь потенциал, необходимо применять специализированные техники и оптимизации. Расскажем о том, как команда разработчиков на базе PyTorch смогла добиться примерно двух с половиной раз ускорения модели Flux без существенного ущерба для качества при помощи глубокой интеграции с современными методами оптимизации.
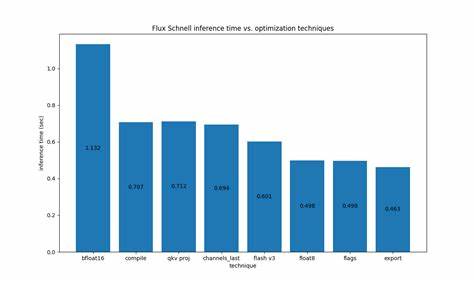
Прежде всего, важно понимать, что модели диффузии требуют значительных вычислительных затрат. Они не поддаются тому же набору оптимизаций, который применяется к языковым моделям и другим типам сетей, особенно когда речь идет о снижении затрат на коммуникацию между центральным и графическим процессорами. Оптимизационные усилия нацелены на минимизацию переходов CPU-GPU, уменьшение количества графических инвалидирований и повышение плотности вычислений. Одной из основных основ успеха стала реализация и применение флагов в torch.compile, таких как fullgraph=True и max-autotune, которые позволяют использовать CUDA Graphs.
Это специальный инструмент, оптимизирующий граф вычислений, способствуя сокращению накладных расходов и повышению скорости пропуска. Следующий шаг сегодня — оптимизация операций внимания, где ключевую роль играют проекции ключа, значения и запроса (q,k,v). Для Flux это означало комбинирование этих операций, что позволило значительно повысить плотность вычислений. Особенно это полезно при квантовании модели, когда размерность становится толще, а значит, приложение может использовать ресурсы GPU более эффективно. Одним из значимых нововведений является использование формата памяти torch.
channels_last для выхода декодера. Этот формат улучшает доступ к данным в памяти и ускоряет вычисления, позволяя модели быстрее обрабатывать результаты и получать отклик. Flash Attention v3 с конвертацией входных данных в формат torch.float8_e4m3fn также стал важной вехой. Этот подход отвечает за оптимизацию операций внимания с помощью специализированных форматов чисел с плавающей точкой уменьшенной разрядности, что значительно снижает требования к памяти и ускоряет вычисления, сохраняя при этом высокое качество результата.
Квантование является той областью, в которой удалось наиболее отчетливо повысить уровень быстродействия без критического ухудшения визуального качества. Используя динамическое квантование активаций и квантование весов линейных слоев посредством torchao’s float8_dynamic_activation_float8_weight, разработчики смогли добиться заметной экономии ресурсов. Интересно, что несмотря на то, что FP8 квантование несколько снижает качество изображения, разница в большинстве случаев минимальна и незаметна для человеческого глаза. Особое внимание было уделено оптимизациям, связанным с компилятором PyTorch Inductor. Были применены специфические параметры, среди которых conv_1x1_as_mm, epilogue_fusion, coordinate_descent_tuning и coordinate_descent_check_all_directions.
Эти настройки позволяют управлять внутренними алгоритмами компиляции и подбором оптимальных конфигураций для приложения, что положительно сказывается на производительности. Параллельно активировались такие возможности, как torch.export и Ahead-of-time Inductor (AOTI), а также включались и использоваться CUDA Graphs, что позволяло повысить насыщенность вычислительных потоков и уменьшить накладные расходы на запуск ядер GPU. Особое внимание исследователей уделялось снижению количества синхронизаций между CPU и GPU. Оказалось, что на первом шаге цикла денойзинга происходит нежелательная синхронизация, вызванная работой планировщика.
Добавление команды self.scheduler.set_begin_index(0) в начале цикла позволило устранить этот узкий горлышко. Особенно важно это в сочетании с torch.compile, поскольку каждый синк вынуждает CPU ждать окончания операций на GPU, что негативно сказывается на общей скорости вычислений.
Сравнительный анализ и визуальные примеры показывают, что большинство оптимизационных техник не влияют на качество создаваемых изображений, за исключением случаев использования FP8 квантования, где влияние минимально и периферийно. Это доказывает, что даже значительная оптимизация и переход на низкоразрядные форматы могут оставаться невидимыми для конечного пользователя. Подводя итог, можно утверждать, что сочетание современных функций компилятора PyTorch, улучшений в управлении памятью, пересмотр конвейеров внимания и грамотного использования квантования значительно повышает эффективность работы с моделями Flux на графических процессорах H100. Такой комплексный подход открывает новые горизонты в задачах генерации изображений, позволяя добиться новой скорости и эффективности без ущерба качеству. Не менее важно понимать, что хотя Hopper архитектура предлагает впечатляющие вычислительные возможности, она сопровождается высокой стоимостью.
Поэтому разработчики и исследователи продолжают искать баланс между производительностью и доступностью, предлагая пользователям различные оптимизации, совместимые с torch.compile и подходящие для более скромных графических решений. Диффузионная библиотека Diffusers содержит множество опций и альтернатив, позволяющих подобрать оптимальный путь для конкретных задач и фреймворков. В конечном счете, открытость этих технологий и готовность сообщества делиться своим опытом и результатами создаёт благоприятную среду для постоянного улучшения и внедрения новых методик ускорения. Каждый желающий может испытать описанные подходы, применить их к своим моделям и внести свой вклад в развитие высокопроизводительных решений.
В сумме, оптимизация Flux на H100 является наглядным примером баланса между технической сложностью и эффективностью. Использование современных инструментов PyTorch и новейших возможностей GPU позволяет существенно сокращать время вычислений, уменьшать затраты на ресурсы и открывать новые возможности для творчества и науки. В ближайшем будущем можно ожидать появления ещё более продвинутых решений, которые сделают искусственный интеллект и генерацию визуального контента ещё более доступными и качественными.





![[LIVE] XRP Price Prediction: John Deaton Says $100B Ripple Valuation Is Possible – Here’s What That Means for XRP](/images/5D132850-340D-4C61-9BCA-9E4E268C7FB6)