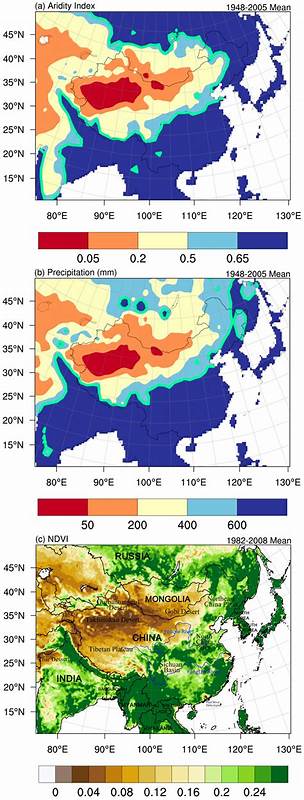
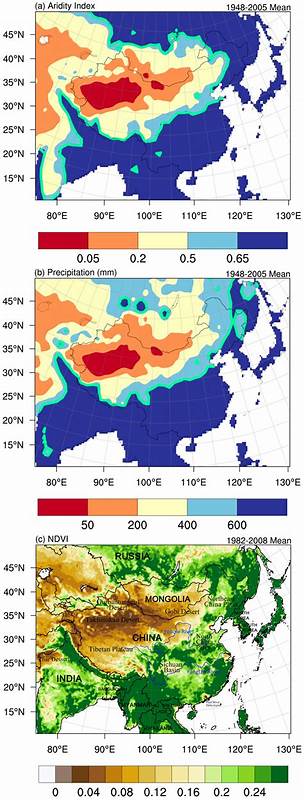
В современной разработке программного обеспечения огромное значение приобретает эффективное использование памяти и скорость доступа к данным. Одним из важных аспектов, влияющих на эти параметры, является способ компоновки структур данных в памяти, особенно когда речь идет о суммируемых типах (sum types) и их тегах. Неправильный порядок хранения тега и полезной нагрузки может привести к значительному перерасходу памяти и снижению производительности. Рассмотрим, почему хранение тегов после полезной нагрузки может существенно улучшить ситуацию, и как это отражается в практиках современных языков программирования. Для начала нужно понять, что оптимизация размещения данных в памяти напрямую связана с выравниванием.
Выравнивание — это требование процессора, чтобы данные определенного размера находились по адресам, кратным их размеру. Например, 4-байтовое целое должно быть расположено по адресу, кратному 4. Несоблюдение этого требования может вызвать как небольшие замедления, так и критические ошибки, в зависимости от архитектуры процессора. В большинстве современных процессоров загрузка данных с правильно выровненного адреса происходит гораздо быстрее и безопаснее. Когда речь заходит о простых типах, таких как целые числа или байты, выравнивание определяется их размером.
Но у структур ситуация сложнее. Структура состоит из нескольких полей, каждое из которых требует определенного выравнивания. Компилятор должен рассчитать общее выравнивание структуры, обычно равное наибольшему требованию её полей. Чтобы обеспечить корректное выравнивание, поля иногда дополняются пустыми байтами (паддингом), что ведет к увеличению размера структуры и, соответственно, к дополнительным расходам памяти. Приведем пример на примере структуры, которая содержит байт и 64-битное целое число.
Если разместить байт в начале структуры, он занимает первый байт, а 64-битное число должно начинаться с адреса, кратного 8. Значит, между байтом и числом появляется отступ, чтобы выровнять число. Всего структура может занять 16 байт, хотя сумма размеров полей составляет всего 9 байт. Такой подход довольно распространен и часто неизбежен. Еще более серьезные проблемы возникают при вложенных структурах или массивах структур.
Если структура имеет нестандартный размер, не кратный её выравниванию, то при создании массива таких структур компилятор должен округлять размер каждой структуры до нужного числа для правильного выравнивания следующей. Это приводит к дополнительным затратам памяти, так как эти «пустые» байты не используются для хранения данных. Swift предлагает инновационный подход к решению этой проблемы, разделяя понятия размера и «шага» (stride) структуры. Размер отражает реальное необходимое количество байт для хранения полей, а шаг гарантирует необходимое выравнивание для массива таких структур. При последовательном хранении в памяти учитывается шаг, что позволяет экономить значительное количество памяти, особенно при работе с глубоко вложенными структурами.
Как это связано с суммируемыми типами? Суммируемые типы, или перечисления с данными, в основном состоят из тега — который определяет, какой вариант используется, и полезной нагрузки, хранящей данные варианта. Традиционно тег размещают перед полезной нагрузкой, что приводит к необходимости выравнивать тег в соответствии с максимальным выравниванием содержимого. Это часто приводит к увеличению общего размера структуры и появлению пустого пространства. Рассмотрим классический пример, на котором построено большинство языков: Option<T>. Этот тип может быть либо значением T (Some), либо отсутствовать (None).
Если тег расположен перед полезной нагрузкой, компилятор выравнивает структуру под максимальный размер и выравнивание полезной нагрузки, что зачастую приводит к большому размеру в памяти. Например, для Option<u64>, где полезная нагрузка — это 8-байтовое целое число, структура будет занимать 16 байт. Однако, в Swift применен иной способ компоновки: тег размещается после полезной нагрузки. За счет этого порядок выравнивания меняется, и структура Option<u64> занимает всего 9 байт — 8 байт полезной нагрузки и 1 байт тега. При этом массив таких значений выравнивается по 16 байтам вследствие требований процессора, но внутри отдельного значения экономится значительное количество памяти.
Это решение особенно ценное при работе с глубоко вложенными или рекурсивными суммируемыми типами. При традиционной компоновке размер экспоненциально растет с увеличением глубины вложенности из-за накопления паддинга и выравнивания. Перестановка тега после полезной нагрузки уменьшает эту проблему, позволяя существенно экономить память и повышать эффективность данных. Еще один важный аспект касается компиляторов современных языков, например Rust. Rust оптимизирует компоновку суммируемых типов, используя пространство неиспользуемых значений в тегах, что позволяет уменьшать размеры вложенных Option.
Однако подобная оптимизация основана на сложных анализах значений тегов и не всегда применима для всех комбинаций или языков. Возвращаясь к концепции хранения тега после полезной нагрузки, стоит отметить, что это решение не только уменьшает общий размер структур, но также может приводить и к положительным эффектам с точки зрения производительности. Правильное выравнивание и компактность данных способствуют повышению эффективности кэширования процессора и снижению количества операций загрузки и хранения в памяти. Для практического применения этих знаний разработчикам необходимо быть внимательными при дизайне структур и суммируемых типов, а также учитывать особенности компилятора и целевой платформы. Некоторые языки и компиляторы позволяют вручную задавать порядок полей или использовать атрибуты, влияющие на выравнивание и компоновку.