Современные системы на основе больших языковых моделей (LLM) стремительно развиваются и находят применение в самых различных областях — от поисковых систем до интеллектуальных ассистентов и автоматизации бизнес-процессов. Одной из ключевых задач в создании этих систем является оптимизация способов взаимодействия языковой модели с внешними инструментами: поисковыми движками, калькуляторами, API и другими специализированными сервисами. Традиционный подход, основанный на прямом вызове LLM для решения задач выбора инструментов и интерпретации результатов, имеет ряд существенных недостатков, которые негативно сказываются на масштабируемости, скорости обработки запросов и стоимости эксплуатации инфраструктуры. Именно в этом контексте появляется перспективное решение — использование дифференцируемого программирования для создания локальных, обучаемых маршрутизаторов, способных эффективно принимать решения о выборе инструментов без привлечения самого языкового процессора на каждом этапе. Классические архитектуры агентских систем зачастую строятся на цепочках вызовов моделей.
В простом сценарии первичная LLM получает запрос, на основании которого определяет, какой инструмент задействовать. После этого вызывается сам инструмент, будь то поиск по базе знаний, калькулятор или любой другой API. Затем следующая LLM-инстанция обрабатывает результаты работы инструмента и формирует итоговый ответ пользователю. Несмотря на очевидную простоту такой схемы и удобство быстрого прототипирования, она плохо масштабируется. Каждый вызов модели несет расходы времени исполнения, средств на оплату использования облачных сервисов и увеличивает количество обрабатываемых токенов, что особенно критично для моделей с жесткими ограничениями по контексту.
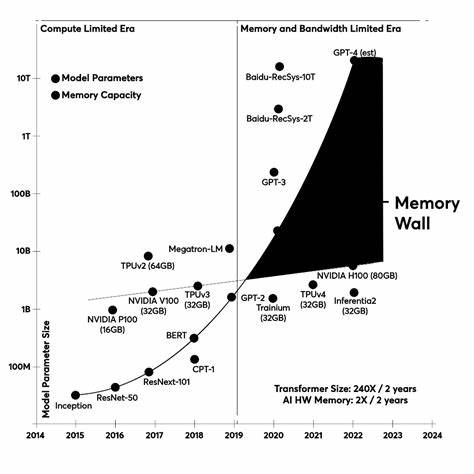
Одной из ключевых проблем является экспоненциальный рост контекстного окна. Каждый промежуточный шаг добавляет к запросу промежуточные данные, историю диалогов и логи вычислений, что приводит к эффекту размывания внимания модели и повышает риск усечения важной информации. В итоге это не только увеличивает задержки и издержки, но и снижает качество выводов модели за счет «утечки» управляющей логики в финальный вывод, а также затрудняет диагностику и отладку. Предложенное решение заключается в отделении задач маршрутизации и выбора инструментов от самого языкового ядра путем создания дифференцируемого контроллера — нейросетевой модели, обучаемой принимать решения о выборе инструмента непосредственно на основе входного запроса. Такой контроллер реализуется с помощью знакомых разработчикам средств дифференцируемого программирования, например, PyTorch, и интегрируется в DSPy-пайплайны — системы для создания и оптимизации агентских рабочих процессов.
Использование локального и обучаемого маршрутизатора имеет несколько важных преимуществ. Во-первых, подобный контроллер работает вне пределов модели LLM, что позволяет избежать многократных дорогостоящих вызовов облачных API. Во-вторых, детерминированная природа контроллера исключает риск случайных отклонений в выборе инструментов, присущий стохастическим языковым моделям. Также такой подход улучшает модульность архитектуры, облегчая интеграцию, тестирование и отладку отдельных компонентов, что крайне важно для сложных систем с множеством взаимосвязанных модулей. Простой пример реализации — компактная четырехслойная нейросеть, принимающая на вход токенизированный текст запроса и выдающая вероятностное распределение по набору доступных инструментов.
Благодаря дифференцируемости контроллера можно применять обратное распространение ошибки на основе конечной задачи или вознаграждения в рамках обучения с подкреплением. Такой метод позволяет накапливать знания и улучшать качество выбора инструментов без привлечения основной LLM к рутинным вычислительным операциям. Обучение контроллера может выполняться как на реальных логах взаимодействия с инструментами, так и на синтетических данных, созданных с помощью генеративных моделей. Это существенно снижает расходы на разработку и внедрение новых инструментальных модулей, будучи однократным вложением против продолжительных затрат на многократные вызовы GPT-4 или аналогичных сервисов. Переход к дифференцируемым маршрутизаторам отражает более широкую тенденцию разделения логики управления и генеративного вывода.
Современные агентские архитектуры зачастую совмещают контроль и языковое моделирование в едином потоке, что приводит к излишнему связыванию процессов и уменьшению гибкости. Разделение нагрузок позволяет LLM сосредоточиться на творческом и когнитивном аспектах задачи, в то время как легковесные нейросетевые модули берут на себя управление потоками задач, оркестрацию и принятие решений на основе локальных данных. Такой подход улучшает масштабируемость систем, позволяя строить более сложные цепочки инструментов без пропорционального увеличения затрат и снижения производительности. При использовании LLM для всего цикла, добавление каждого нового шага увеличивает количество вызовов модели, приводя к росту времени отклика и затрат, а также утяжелению контекста и риску потери информации. Дифференцируемое программирование устраняет эти изъяны, обеспечивая стабильный объем контекста и более предсказуемое поведение системы.
Практические выгоды от внедрения данной технологии заметны уже на ранних этапах. В качестве оценки можно рассмотреть пример маршрутизатора, который распределяет задачи между поисковым модулем и калькулятором. Вместо трех последовательных вызовов GPT-4 (планирование, интерпретация, формирование ответа) на каждый запрос достаточно одного обученного контроллера и одного окончательного вызова LLM, что приводит к уменьшению затрат минимум втрое. Чем больше комплексность системы и количество задействованных инструментов, тем выше экономия. Кроме экономии ресурсов, дифференцируемый подход приносит улучшения и в плане качества выходных данных.
Отделение управляющей логики повышает прозрачность процесса, облегчает диагностику ошибок и настройку параметров. Уменьшается вероятность случайных галлюцинаций модели за счет уменьшения контекста, непосредственно связанного с управляющей информацией. Использование таких контроллеров становится частью нового стандарта в построении AI-агентов, выводя системы на уровень, где они больше напоминают традиционные компьютерные программы с четко разграниченными слоями управления и исполнения, чем последовательные цепочки вызовов LLM. Это открывает путь для новых архитектур, которые будут более гибкими, экономичными и адаптивными без потери качества интеллектуальных функций. Подытоживая, можно сказать, что дифференцируемое программирование для выбора инструментов в рабочих процессах с большими языковыми моделями приносит революционные изменения в подходах к построению современных AI-систем.
Этот метод позволяет не только снижать издержки и ускорять обработку запросов, но и улучшать масштабируемость, управляемость и объяснимость процессов. В сочетании с мощными фреймворками, такими как PyTorch и DSPy, дифференцируемые маршрутизаторы становятся надежным фундаментом для будущих поколений интеллектуальных агентов, способных эффективно использовать разнообразные инструменты, сохраняя при этом высочайшее качество генерации и синтеза информации.