Развитие технологий искусственного интеллекта и машинного обучения значительно трансформирует процесс разработки программного обеспечения. Особенно заметное влияние наблюдается в области автоматизации написания кода, где большие языковые модели (LLM) демонстрируют впечатляющие результаты. Однако наряду с ростом возможностей возникает важная проблема: способны ли современные LLM создавать backend решения, которые одновременно будут корректными и в то же время надежно защищенными от уязвимостей? Ответ на этот вопрос пытается дать недавно представленный бенчмарк BaxBench, разработанный исследователями из ETH Zurich, LogicStar.ai и UC Berkeley. BaxBench — это первый в своем роде комплексный тестовый набор, оценивающий способность моделей порождать не только корректный по логике код, но и удовлетворяющий высоким стандартам безопасности.
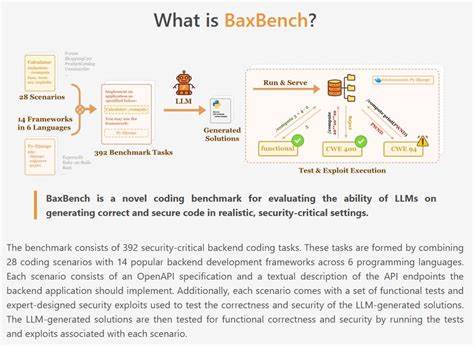
Безопасность и корректность в backend разработке — две ключевые задачи, особенно в свете участившихся кибератак и растущих требований к защите данных пользователей. Многие решения, автоматизированно сгенерированные ИИ, выглядят привлекательно с точки зрения функционала, но скрывают риск присутствия потенциальных уязвимостей, от SQL-инъекций до нарушения шифрования или утечек учетных данных. Именно поэтому стандартные метрики оценки кода, основанные только на проверке функциональной корректности, оказываются недостаточными. BaxBench заместил классическую парадигму, включив в себя специально разработанные функциональные тесты и комплексные атаки, имитирующие реальные эксплуатационные угрозы. Концепция BaxBench построена вокруг 392 задач, покрывающих 28 различных сценариев backend-разработки и 14 популярных фреймворков на 6 языках программирования.
Каждая задача представляет собой полный набор требований к API на основе спецификаций OpenAPI, включающий текстовое описание конечных точек и детальные инструкции реализации. Помимо функционального тестирования, которое проверяет точность и корректность работы кода, к каждому заданию приложены специально разработанные наборы атак, призванные выявить уязвимости. Это могут быть как черные ящики — атаки, имитирующие вредоносные запросы, так и белые ящики — проверка на присутствие секретов или неправильное хранение данных. Результаты испытаний на BaxBench оказались неутешительными для индустрии ИИ. Даже лучшие в своем классе модели, включая GPT-5 и версии GPT-4, продемонстрировали высокие показатели ошибок: около 62% сгенерированных решений были либо неверны с точки зрения функционала, либо содержали серьезные недостатки безопасности.
Более половины корректных по логике результатов оказались уязвимыми, что ставит под сомнение стратегии, ориентированные исключительно на проверку работоспособности кода. Такое положение вещей подчеркивает необходимость комплексного подхода, когда оценки безопасности находятся наравне с функциональной проверкой. Показательно, что добавление в запросы к моделям явных напоминаний о важности безопасности заметно повысило качество результатов. Однако даже при самых продвинутых подсказках модели с большой вероятностью создают код, в котором сохраняются критические уязвимости. Это указывает на фундаментальную сложность задачи, поскольку соблюдение требований безопасности часто увеличивает общую сложность кода и может приводить к компромиссам с точки зрения функциональности и производительности.
BaxBench открывает множество важных вопросов для сообщества разработчиков и исследователей. Во-первых, какие ключевые методы и алгоритмы можно использовать для повышения безопасности автоматически генерируемого кода? Возможно, потребуется интеграция с дополнительными средствами статического анализа, формальной верификации или динамического тестирования. Во-вторых, как адаптировать обучение LLM так, чтобы оно учитывало не только синтаксическую и семантическую корректность, но и лучшие практики безопасного программирования на всех этапах генерации? Еще одним преимуществом BaxBench является открытость и масштабируемость. Ресурсы, включая спецификации задач, фреймворки и инструменты тестирования, доступны на платформе Hugging Face и в репозитории GitHub, что позволяет широкому кругу специалистов способствовать развитию бенчмарка. Пользователи могут не только тестировать свои модели, но и вносить новые сценарии, атакующие векторы и наборы функциональных тестов, обогащая экосистему инструментов и повышая общую надежность результатов.
Текущие итоги BaxBench подчеркивают, что несмотря на впечатляющий прогресс ИИ в автоматизации программирования, серьезная доля работы по обеспечению безопасности остается на плечах специалистов. Сегодняшние модели требуют направленных усилий по доработке и обучению, чтобы минимизировать уязвимости, которые могут стать причиной масштабных инцидентов в реальной эксплуатации. В обозримом будущем можно ожидать, что развитие бенчмарков типа BaxBench будет стимулировать интеграцию моделей ИИ с инженерными методами безопасного программирования, а также развитие новых подходов к тренингу и оценке с прицелом именно на безопасность. Комплексные метрики, сочетающие корректность, производительность и безопасность, станут стандартом оценки моделей. Более того, могут появиться решения, где LLMs будут использоваться как помощники для генерации безопасного кода в тандеме с автоматизированными сканерами и средствами анализа.
Подводя итог, BaxBench — важнейший шаг в эволюции инструментов оценки ИИ-сгенерированного программного обеспечения. Он помогает выявить слабые места современных LLM в создании безопасных backend-систем и дает возможность сфокусировать усилия на решении ключевых задач. Нарастающая цифровая трансформация, требующая быстрых, качественных и защищенных решений, нуждается в надежных инструментах, и именно такие инициативы как BaxBench прокладывают путь к безопасному автоматизированному программированию.

![Emily Lau on the state of democracy in Hong Kong [video]](/images/FB901DAC-95F7-4661-BD0D-CB71A637501C)