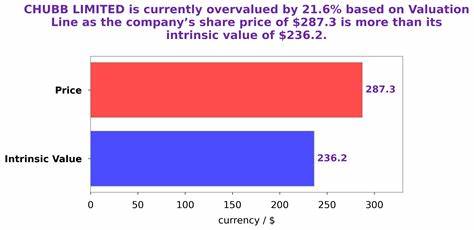
Информационный поиск сегодня представляет собой нечто большее, чем просто нахождение документов по ключевым словам. Современные технологии, такие как векторные базы данных и модели векторных представлений, открывают новые горизонты для понимания и обработки данных, делая поиск более точным и интеллектуальным. Мой опыт работы в компании Weaviate, специализирующейся на векторных базах данных, позволил погрузиться глубоко в эту динамично развивающуюся область и изучить множество нюансов, которые помогают создавать эффективные и масштабируемые решения. Одним из первых открытий стало то, что классический подход с использованием BM25 остается мощной и эффективной основой для поиска. В мире, где часто считают, что векторный поиск — это единственная современная методика, важно не забывать о том, что простые и проверенные алгоритмы прекрасно справляются с базовыми задачами и зачастую являются отличной отправной точкой.
BM25 хорош тем, что быстро вычисляется и дает релевантные результаты на основе частоты и распространенности терминов, что позволяет эффективно фильтровать документы. Тем не менее, когда речь заходит о поиске по большому объему данных с учетом семантики и контекста, векторные базы данных становятся незаменимыми. Векторный поиск позволяет находить информацию не только по точному совпадению ключевых слов, но и по смысловой близости. Однако стоит помнить, что векторный поиск является приближённым по своей природе. Для ускорения обработки применяется Approximate Nearest Neighbor (ANN) — набор алгоритмов, среди которых особое место занимают HNSW, IVF и ScaNN.
Эти методы обеспечивают баланс между скоростью и точностью, что критично при работе с масштабными хранилищами данных. Важным аспектом является то, что векторные базы данных не ограничиваются хранением только векторных эмбеддингов. Помимо этого, они сохраняют исходные объекты, например, текст, из которого были построены векторы, а также метаданные. Такой подход позволяет комбинировать разные типы поиска — как векторный, так и классический ключевой, а также осуществлять фильтрацию по метаданным, создавая гибридные поисковые системы высокой эффективности. Нельзя упускать из виду и тот факт, что основное применение векторных баз данных — это не генеративный искусственный интеллект, а поиск и извлечение релевантной информации.
Взаимодействие с крупными языковыми моделями (LLM) напрямую связано с поиском контекста для генерации качественных ответов. Поэтому векторные базы данных являются фундаментом, на котором строится эффективный поиск и обработка больших объемов текстовой информации. Одно из важных и часто недооцененных требований работы с векторным поиском — необходимость задавать количество возвращаемых результатов. Спонтанное представление о том, что система автоматически выдаст оптимальное множество документов, ошибочно. На самом деле для оптимальной работы запросов нужно явно указывать максимальное число элементов, что позволяет контролировать качество и скорость отклика системы.
Разнообразие типов векторов и эмбеддингов заслуживает особого внимания. Наиболее привычными являются плотные (dense) векторы, в которых каждый элемент представляет собой вещественное число, отражающее степень принадлежности к определенному признаку. Однако существуют также разреженные векторы, бинарные и даже мультиизмерные эмбеддинги. Каждый из этих видов подходит для специфических задач, и понимание их особенностей помогает подобрать наиболее подходящее решение. Одна из ключевых возможностей — использование различных моделей для получения эмбеддингов.
Огромную помощь в выборе оказывают специализированные бенчмарки, такие как Massive Text Embedding Benchmark (MTEB) и BEIR, которые позволяют оценивать модели по разнообразным критериям от классификации до семантического поиска. При работе с многоязычными или нерусскоязычными текстами стоит ориентироваться на MMTEB, который учитывает многокультурные и лингвистические особенности. История развития эмбеддингов показывает эволюцию от статических моделей, таких как Word2Vec и GloVe, к более гибким и контекстным, представленным BERT и его производными. Статические модели остаются актуальными в условиях ограниченных ресурсов, так как позволяют быстро извлекать предвычисленные векторы без необходимости повторного обучения, что особенно полезно в встраиваемых и низкопроизводительных системах. Интересным моментом является различие между разреженными векторами и разреженными эмбеддингами.
Разреженные вектора могут быть получены распределенными методами, такими как TF-IDF или BM25, с помощью классических индексов обратных ссылок, тогда как разреженные эмбеддинги создаются нейросетевыми моделями, например, SPLADE. Понимание этого различия позволяет точнее выбирать инструменты для конкретных задач. Расширение возможностей поиска за пределы текста чрезвычайно интересно. Сегодня векторные представления применяются к изображениям, PDF-документам, графам и другим типам данных, что даёт шанс создавать мультимодальные поисковые системы. Такой подход открывает новые перспективы и делает информационный поиск более универсальным и адаптивным.
Экономическая сторона внедрения векторных эмбеддингов не менее важна. Размерность вектора напрямую влияет на затраты по хранению и скорости обработки. Хотя более высокое количество измерений способно захватывать более тонкие семантические нюансы, часто для многих прикладных задач достаточно и меньшей размерности, что позволяет значительно сокращать требования к инфраструктуре. Постоянное использование моделей эмбеддингов — обязательное условие работы современных поисковых систем. Каждый запрос должен быть преобразован в вектор, и для новых добавлений или изменений данных требуется повторное вычисление и индексирование, что также стоит учитывать при проектировании системы.
Осторожность нужна в вопросе интерпретации результатов векторного поиска. Высокая близость по векторному пространству не всегда гарантирует релевантность. Например, предложения «Как починить кран» и «Где купить кухонный кран» могут быть близки в смысле слов, но отражают разные поисковые цели. Это требует грамотной настройки и последующего анализа результатов. Интересным техническим моментом является различие между косинусной похожестью и косинусным расстоянием — взаимопротивоположными величинами, где большая похожесть означает меньшую дистанцию.
При работе с нормализованными векторами эффективность повышается за счет использования скалярного произведения, что математически эквивалентно вычислению косинусной похожести. Распространено заблуждение, что в аббревиатуре RAG буква R означает «vector search», однако правильнее трактовать её как «retrieval» (извлечение), что охватывает широкий спектр технологий, включая ключевый поиск, фильтрацию и переупорядочивание. Комбинация различных методов поиска позволяет создать гораздо более мощные и гибкие системы. Использование гибридного поиска, сочетающего семантический векторный и точный ключевой поиск, обеспечивает достижение лучшей релевантности, особенно когда запросы требуют одновременного учета смысла и конкретных терминов. Современные платформы предлагают возможность настройки весов этих компонентов через параметры, что значительно упрощает адаптацию под уникальные требования.
Тем не менее, ошибочно думать, что применение фильтрации всегда ускоряет векторный поиск. На практике фильтры могут нарушать внутренние структуры индекса, например, графы HNSW, что приводит к снижению качества результатов или даже их отсутствию. Современные системы разрабатывают сложные методы работы с фильтрами, чтобы минимизировать эти эффекты. Двухступенчатые пайплайны извлечения применяются не только в рекомендательных системах. Они отлично подходят и для систем, объединяющих поиск и генерацию контента, где на первом этапе происходит быстрое предварительное отбор, а на втором — более точное переупорядочивание результатов с учетом дополнительных критериев.
Подбор оптимального размера фрагментов для эмбеддинга — нетривиальная задача. Слишком маленькие части теряют контекст, а слишком большие — размывают смысл. Аналогия с киноафишей, где совмещаются все кадры фильма, хорошо иллюстрирует риски избыточной агрегации информации. Именно поэтому выбор моделей с учетом размера контекстного окна становится ключевым при построении глубинного поиска. Стоит разграничивать понятия векторных индексов и векторных баз данных.
Хотя обе технологии обеспечивают быструю работу с векторами, базы данных, помимо этого, предлагают полный набор инструментов для управления данными, включая сохранение, создание, обновление и удаление объектов, а также фильтрацию и гибридные виды поиска. С течением времени рынок высказывает предположения о снижении актуальности процессов RAG ввиду появления LLM с большими контекстными окнами. Тем не менее, опыт показывает, что традиционные методы извлечения сохраняют свою значимость, поскольку подходят для множества практических сценариев и позволяют поддерживать высокую эффективность без чрезмерных затрат. Важной оптимизационной техникой является векторная квантизация, позволяющая значительно уменьшить объем хранения за счет преобразования сложных векторов в бинарные или разреженные представления с минимальными потерями точности. Этот подход эффективен для масштабируемых систем, где экономия ресурсов — критичный фактор.
Стереотип о том, что векторный поиск устойчив к опечаткам, не всегда верен. Ввиду недостаточности вариативности опечаток в обучающих данных модели не всегда способны адекватно обрабатывать неправильное написание, что требует от разработчиков продумывать дополнительные слои коррекции и обработки запросов. Выбор правильных метрик оценки поисковых систем — ключевой этап разработки. Кроме известных precision и recall, существуют более сложные меры, учитывающие порядок выдачи, такие как MRR, MAP и NDCG. Понимание сути и преимуществ каждой из них позволяет адаптировать поиск под требования конкретных бизнес-задач.
Не менее важным является выбор и настройка токенизаторов. Помимо популярных Byte-Pair-Encoding, существуют и другие техники разбиения текста, серьезно влияющие как на производительность ключевого поиска, так и на качество гибридных систем. Тонкость состоит в различении понятий «out-of-domain» и «out-of-vocabulary». Современные модели благодаря продвинутой токенизации умеют обрабатывать незнакомые слова, однако если термин не встречается в области применения, его векторное представление может не содержать осмысленной информации, что негативно сказывается на результатах Оптимизация запросов для векторного поиска становится важным навыком. Переход от привычных формулировок, как в традиционных поисковых системах, к более семантически релевантным запросам — это естественный этап в обеспечении высокой точности извлечения информации.
Эволюция информационного поиска движется от простого ключевого сопоставления к машинному обучению, через векторные методы к системам, использующим языковые модели с расширенными способностями к рассуждению, что открывает новую эпоху в разработке интеллектуальных поисковых решений. Погружение в сферу информационного поиска — это непрерывный процесс изучения и совершенствования. Векторные базы данных, гибридные методы и интеграция с современными языковыми моделями создают уникальный набор инструментов, делающий поиск эффективным, масштабируемым и адаптированным под самые разнообразные требования современного цифрового мира. Опыт работы с этими технологиями подтверждает, что ключевым остается качество найденной информации и её релевантность для конечного пользователя, что стимулирует дальнейшие исследования и инновации в области информационного поиска.