SQLite — это одна из самых популярных и легковесных систем управления базами данных, которая применяется во множестве приложений и систем. Несмотря на свою простоту и компактность, она обладает мощным механизмом обработки данных любого объема. Одной из важных особенностей является способность эффективно работать с большими строками и бинарными объектами (BLOB), которые могут превышать размер стандартной страницы базы данных. В данной публикации мы рассмотрим механизм переполнения страниц SQLite и реализуем его в собственной минималистичной базе данных на Rust, что позволит работать с данными, превышающими размер одной страницы. В повседневной работе с базами данных часто приходится иметь дело с полями, размер которых значительно превышает стандартный размер страницы, установленный в SQLite (обычно 4096 байт).
Это происходит, например, при хранении больших текстовых документов, изображений или других бинарных объектов. В простых тестовых базах данных, как правило, данные помещаются в одну страницу и это упрощает доступ и хранение. Однако реальная ситуация гораздо сложнее – большая часть полей может выходить за пределы одной страницы. Для решения этой задачи SQLite применяет систему переполнения страниц, благодаря которой данные разбиваются и хранятся линейно на нескольких связанных страницах. Основной принцип хранения переполненных данных заключается в том, что первые несколько байт каждой страницы зарезервированы для хранения указателя на следующую страницу переполнения.
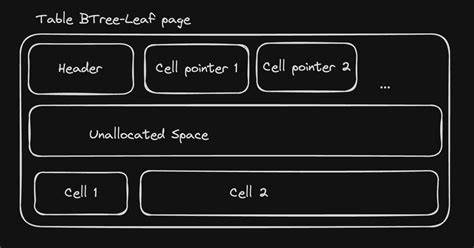
Таким образом, все Overflow pages формируют цепочку, или связанный список, который можно последовательно прочесть для восстановления полного содержимого. В структуре B-tree ячейки самой страницы хранится лишь часть данных (локальный payload), а начиная с конца локальной части, следует указатель на первую страницу переполнения, если таковая имеется. Для реализации поддержки переполнения в нашей базе данных сначала необходимо точно определить максимально доступный размер полезных данных на странице. Для этого учитывается общее количество байт, отведенных под страницу (page size), и количество байт, зарезервированных системой для внутренних нужд или расширений (page reserved size). Вычисление размера полезного пространства страницы играет ключевую роль в определении, какую часть полезной нагрузки хранить непосредственно в ячейке, а какую отправлять на переполнение.
Далее для вычисления локального размера полезной нагрузки используется особая формула из SQLite. Она предусматривает несколько пороговых значений: если объем данных меньше определенного порога X (U - 35, где U — полезный размер страницы), то данные помещаются целиком внутрь ячейки. В случае, если объем данных превышает этот порог, необходимо определять локальный размер с использованием сложной формулы, учитывающей минимальный (M) и максимальный (K) локальные размеры, рассчитываемые через вычисления с учетом размера страницы. Это важно, чтобы оптимально распределить данные между локальной частью и страницами переполнения и обеспечить эффективное считывание данных с диска. Для загрузки и непосредственного чтения переполненных страниц в нашей реализации создается структура OverflowPage, которая хранит указатель на следующую страницу и данные переполнения.
Чтение таких страниц требует специального механизма, который последовательно читает все страницы переполнения, объединяя их содержимое для полного восстановления данных ячейки. Незначительное изменение затрагивает и кеширование страниц в нашем Pager. Вместо хранения только страниц с основной структурой базы данных, теперь Pager должен поддерживать хранение как обычных страниц, так и страниц переполнения. Для этого вводится перечисление CachedPage, позволяющее различать типы страниц. Создаются конвертации и обработчики для безопасного и эффективного взаимодействия с обоими типами.
Это обеспечивает единый интерфейс доступа к страницам базы данных, облегчая управление памятью и повышая производительность. Одним из важных этапов является внедрение ленивого чтения переполненных данных. При запросе поля с курсора сначала проверяется, входит ли данные поля в локальную полезную нагрузку. Если размер поля превышает локальный размер, то для считывания недостающей части данных вызывается OverflowScanner, который следует по цепочке переполненных страниц и объединяет содержимое. Такой подход экономит ресурсы, загружая переполненные данные по мере необходимости, а не сразу, что важно при работе с большими объемами данных, которые могут не понадобиться сразу.
Для удобства работы с данными добавляется ряд утилит и методов, позволяющих вычислять границы полей и работать с различными типами данных SQLite. При этом учитывается, что данные могут храниться в нескольких местах: сначала в локальной части, а затем в переполнении. Метод owned_field адаптируется под новую логику, возвращая значение поля, загружая при этом необходимую часть данных с переполнения. В результате реализации всего перечисленного наша база данных способна корректно и эффективно работать с большими текстами и бинарными объектами, не ограничиваясь стандартным размером страницы. Такой подход развязывает руки разработчикам и консультантам по базам данных в применении собственной минималистичной СУБД, открывая возможности хранения и обработки реальных объемов данных.