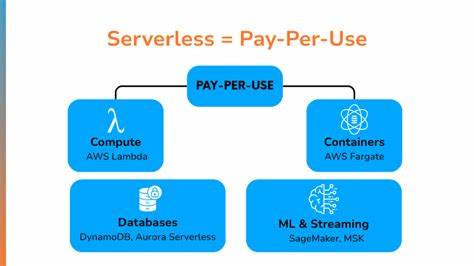
В эпоху интенсивного развития искусственного интеллекта и машинного обучения, разработчики и компании все чаще сталкиваются с одной и той же проблемой — высокой стоимостью использования сложных моделей искусственного интеллекта. Для многих, особенно для независимых разработчиков и стартапов с ограниченным бюджетом, текущие модели тарификации API, основанные на количестве запросов или объеме обработанных данных, оказываются серьезным барьером на пути к инновациям и развитию проектов. В этой связи все больше внимания привлекает идея серверless-подхода с оплатой за фактическое время вычислений — модель, при которой пользователь платит только за секунды использования GPU для исполнения задач AI-инференса. Давайте глубже разберемся, что предлагает эта концепция, ее плюсы и минусы, а также насколько она перспективна и востребована в современном технологическом ландшафте. Что такое серверless и оплата за секунду AI-инференса? Под серверless понимается облачная модель, при которой разработчику не нужно заниматься управлением инфраструктурой — серверы и оборудование полностью скрыты за абстракцией, а пользователь взаимодействует с сервисом, используя API.
В случае AI-инференса такой сервис предлагает отправить запрос с данными (например, текстом, изображением или другой информацией), после чего запрос обрабатывается на GPU, выделенном из общей пуловой инфраструктуры. Оплата происходит по принципу точного учета времени — пользователь платит только за те секунды, в течение которых его задача выполнялась на высокопроизводительном оборудовании. Такой подход кардинально отличается от традиционных моделей тарифов, где плата налагается на количество обработанных токенов, объем данных или фиксированную месячную подписку. Преимущества модели оплаты за секунду AI-инференса для разработчиков Прозрачность расходов — один из ключевых аргументов в пользу данного подхода. Разработчик точно знает, за что он платит и может прогнозировать бюджет, исходя из предполагаемого времени выполнения задач, а не обращая внимания на сложные параметры, которые могут неожиданно увеличить счет.
Гибкость и экономия — пользователи не платят за простой или ожидание, что особенно важно для проектов с нерегулярной нагрузкой или экспериментальных предприятий. Возможность быстро масштабироваться вниз до нуля без дополнительных затрат позволяет оптимизировать расходы, сохраняя доступ к высокопроизводительным ресурсам в нужный момент. Отсутствие необходимости самостоятельного управления GPU-серверами снижает технические и операционные издержки, позволяя сосредоточиться на разработке и запуске продуктов. Недостатки и потенциальные сложности реализации службы серверless AI-инференса Несмотря на очевидные преимущества, у модели есть ряд серьезных вызовов. Стоимость инфраструктуры и оборудования остается высокой, особенно при обеспечении качественного и быстрого отклика.
Управление потенциалом пиковых нагрузок и латентностью требует продвинутых механизмов балансировки и распределения ресурсов. Соперничество с крупными игроками, у которых уже имеются отлаженные платформы и большие вычислительные мощности, создает высокие стартовые барьеры. Стоимость реализации и поддержания пула GPU, а также расходов на электроэнергию, охлаждение и обновление оборудования могут перевесить выгоды от точечного тарифа, если не выбрать удачную бизнес-модель. Экономическая целесообразность сложна из-за высоких изначальных затрат и необходимости достижения критической массы клиентов, чтобы обеспечить устойчивость платформы и низкие цены. Примеры и тенденции на рынке серверless AI-сервисов Современные крупные облачные провайдеры, такие как Google Cloud, экспериментируют с подобными решениями.
Например, Google Cloud Run уже предлагает возможность автоматического масштабирования и тарификации на основе длительности работы с GPU, что делает модель более доступной и прозрачной для разработчиков. Аналогичные инициативы появляются и у других поставщиков, что говорит о растущем интересе к серверless-инфраструктурам для AI-задач. Это позволяет предположить, что рынок движется в сторону большей демократизации доступа к ресурсам для машинного обучения, особенно на ранних этапах разработки и прототипирования. Размышления о будущем и рекомендациях для разработчиков Модель оплаты за посекундное использование GPU для AI-инференса открывает новые возможности для независимых разработчиков и небольших команд, стремящихся создать инновационные продукты без огромных затрат. Однако для того, чтобы такое решение стало массовым, необходимы дальнейшие технологические улучшения, снижение стоимости оборудования и энергопотребления, а также развитие эффективных алгоритмов распределения ресурсов.
Отдельное внимание потребуется уделять безопасности данных и прозрачности работы системы, чтобы пользователи чувствовали уверенность в сервисе. На практике, чтобы быть конкурентоспособным, новый сервис должен не просто предложить инновационную модель тарификации, но и позаботиться о стабильности работы, скорости отклика и качестве поддержки клиентов. Итоги и общие выводы Для многих разработчиков текущие стоимости AI-инференса оказываются слишком высокими, что сдерживает развитие проектов и эксперименты с новыми идеями. Серверless-подход с оплатой за секунду предоставляет возможность более гибкого, прозрачного и экономичного использования сложных моделей искусственного интеллекта. Тем не менее, экономическая эффективность такой модели требует продуманного подхода к инфраструктуре и бизнесу, а также учета технических сложностей при масштабировании.
Будущее этой концепции зависит от того, насколько успешно команды смогут балансировать между высокими затратами на аппаратное обеспечение и привлекательностью для конечных пользователей. Сегодня подобная модель выглядит многообещающей для индивидуальных разработчиков и небольших компаний, желающих максимально оптимизировать расходы без потери доступа к передовым технологиям AI. По мере технологического прогресса и появления новых решений на рынке, стоимость и доступность серверless AI-инференса будут продолжать улучшаться, открывая путь для масштабных инноваций и новых возможностей в области искусственного интеллекта.