Фуззинг как метод тестирования программного обеспечения традиционно играет ключевую роль в выявлении уязвимостей и ошибок. С появлением больших языковых моделей (LLM) появилась новая эпоха возможностей, позволяющая автоматизировать и значительно ускорить этот процесс. Ключевым достижением последнего времени стало масштабирование LLM-фуззинга до обработки миллиардов токенов, что открывает перспективы для более эффективного обнаружения багов и улучшения качества программ. Исследования последних лет свидетельствуют, что LLM-фуззинг представляет собой революционное сочетание искусственного интеллекта с классическими подходами к генерации тестовых данных. Использование таких моделей, как GPT-4.
1 и Codex, позволяет создавать осмысленные и контекстно насыщенные тестовые сценарии, что значительно повышает вероятность выявления скрытых и сложных ошибок в коде. Особенно примечателен факт возможности масштабного применения данной технологии на живых, сложных проектах, включая компиляторы и популярные библиотеки, что ранее казалось затруднительным из-за ограничений производительности и затрат. Практическая реализация LLM-фуззинга была продемонстрирована на примере анализа монорепозитория языка программирования Tact и смежных проектов, включая компиляторы FunC и Tolk, блокчейн платформу TON, а также TypeScript-библиотеку @ton/core. Основной подход заключался в двух направлениях — черный ящик и белый ящик. При черном ящике агентам предоставлялась только документация и ограниченная контекстная информация, что позволяет выявлять баги без знания внутренней реализации.
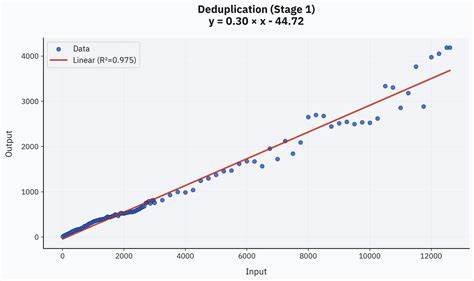
Белый ящик, напротив, давал доступ к исходному коду, что позволяло моделям точечно анализировать уязвимые места и максимально эффективно создавать тесты. Одним из наиболее значимых экспериментов стал масштабный запуск на базе модели quasar-alpha, обработавшей более 14 миллиардов токенов за несколько дней. За это время было сгенерировано сотни тысяч фрагментов кода, успешно выявленных ошибок и уникальных случаев, тестирующих компилятор для языка Tact. Такой объем данных позволил детально изучить закономерности масштабирования эффективности фуззинга, выявляя заметные закономерности в отношениях «входные данные — найденные ошибки». Дедупликация результатов стала важным этапом процесса, помогая отсеивать повторяющиеся или схожие по сути баги и сокращать нагрузку на человеческий фактор в ручном обзоре находок.
Для этого использовалась двухэтапная система, где сначала применялись алгоритмы кластеризации на базе эмбеддингов с использованием современных моделей, а затем интеллектуальное сопоставление при помощи LLM, что позволило свести тысячи исходных обнаружений к сотням уникальных и качественных кейсов. Результаты подтверждают, что, несмотря на конечные затраты, LLM-фуззинг представляет собой экономически оправданный и перспективный подход. Средняя стоимость выявления одной настоящей ошибки составляет примерно 17 долларов при суммарных инвестициях около 2000 долларов, что притом учитывает как бесплатные периоды использования моделей, так и платные API. Качество и объем обнаруженных багов впечатляют — более сотни реальных проблем было зафиксировано и передано на исправление. Сравнительный анализ различных моделей показал важность не только стоимости, но и качества рассуждений модели.
Такие модели, как o4-mini и Gemini 2.5 Pro, демонстрируют оптимальное соотношение цены и эффективности, превосходя более дорогие и менее специализированные версии. Это указывает на необходимость тщательно выбирать модели для масштабных фуззинг-кампаний, акцентируя внимание на логическом осмыслении и способности минимизировать ложные срабатывания. Интересно, что закономерность масштабирования обнаруженных уникальных ошибок подчиняется так называемой квази-степенной зависимости с показателем около четвертой степени (√√N), где N — общее число сгенерированных тестов. Проще говоря, с увеличением объема данных рост полезных результатов происходит медленно, но предсказуемо.
Это объясняет, почему увеличение бюджета на одно большое тестирование менее эффективно, чем распределение ресурсов по широкому спектру небольших и сфокусированных наборов тестов. Белый ящик в данной работе доказал свою высокую эффективность, позволяя выявлять ошибки с меньшими затратами времени и ресурсов, благодаря доступу к исходному коду. Модель Codex подтвердила возможность генерировать воспроизводимые паттерны багов и предлагать по-настоящему ценные инсайты. Однако отмечены трудности с очень большими и сложными базами кода, где модель может теряться в деталях и неверно интерпретировать контекст. Особенности отдельных языковых конструкций и компонентов документации влияют на качество результатов.
Например, стандартные конструкции математических выражений и коллекций обрабатываются значительно лучше, чем специфические для блокчейн-приложений или малоизвестные фичи. Это порождает осознание необходимости более специализированных подходов к обучению и настройке моделей для работы с тематически сложными областями. Будущее направление исследований лежит в полномасштабной автоматизации процесса валидации и публикации обнаруженных багов. Планируется создание автономных агентов, которые смогут не только генерировать и тестировать кейсы, но и проверять их воспроизводимость, искать информацию о наличии подобных багов в репозиториях, а также самостоятельно создавать аккуратные и лаконичные задачи на исправление. Перспектива массового параллельного белого ящика обусловлена улучшением доступа к API с высокими лимитами запросов, что позволит одновременно запускать десятки и сотни агентов, взаимодействующих с различными частями проекта.
Реализация такой масштабируемой архитектуры значительно повысит скорость обнаружения критически важных уязвимостей. Таким образом, синергия больших языковых моделей и современных алгоритмов фуззинга открывает новую эпоху в тестировании ПО, где масштабируемость, точность и экономическая эффективность становятся ключевыми факторами успеха. С постоянным развитием LLM и инструментов их интеграции, можно ожидать, что эти методы вскоре станут стандартом в индустрии разработки, помогая создавать более надежный и безопасный софт.