Современные распределённые системы активно используют протокол gRPC для организации взаимодействия между сервисами благодаря его высокой производительности и поддержке двунаправленного стриминга. Однако на практике, при работе в условиях низкой задержки сети, разработчики сталкиваются с неожиданными ограничениями на стороне клиента, которые значительно снижают эффективную пропускную способность и увеличивают задержки. Понимание данных ограничений и способы их обхода играют ключевую роль для построения высоконагруженных систем с минимальной задержкой. gRPC поверх HTTP/2 предоставляет удобный и эффективный механизм мультиплексирования нескольких потоков сообщений по единому TCP-соединению. Каналы gRPC служат для организации подключения клиента к серверу, при этом каждый канал использует TCP-соединение, по которому распространяются запросы различного типа.
Однако часто разработчики не учитывают, что в gRPC существует ограничение на число одновременных параллельных потоков на одном соединении — стандартно это около 100. Когда это ограничение достигается, дополнительные запросы на стороне клиента начинают ожидать освобождения очереди, что неизбежно влияет на задержку обработки запросов. В условиях низколатентной сети, где коммуникация между клиентом и сервером происходит очень быстро, эти внутрисклиентские лимиты начинают проявляться особенно остро. В реальных экспериментах с использованием простого микробенчмарка на C++, где множество параллельных работников выполняли RPC-вызовы, наблюдался парадоксальный эффект: увеличение числа одновременно работающих клиентов не приводило к линейному росту пропускной способности. Вместо этого рост был сублинейным, а задержка начала расти почти пропорционально количеству параллельных запросов.
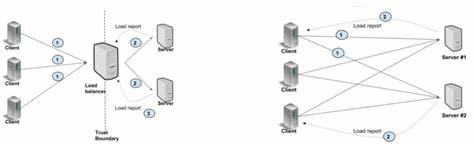
Такое поведение свидетельствует о наличии узкого места именно на стороне клиента, а не из-за сетевых или серверных ограничений. Подробный анализ с помощью инструментов мониторинга и сетевого протоколирования показал, что несмотря на имеющуюся современную инфраструктуру с быстрыми процессорами и низкой задержкой между машинами (в пределах долей миллисекунды), gRPC ограничивал поток запросов через один канал и TCP-соединение. Клиент последовательно отправлял батчи запросов, сервер быстро отвечал и закрывал очередь, после чего следовал период бездействия 150-200 микросекунд, прежде чем начался следующий цикл отправки. Такая пауза обусловлена внутренними механизмами управления мультиплексированными потоками HTTP/2 внутри gRPC-библиотеки и некоторыми узкими местами в системах управления очередями запросов на клиенте. Разработчики пытались обойти данное положение двумя основными способами, рекомендованными в официальной документации gRPC.
Первый — создание отдельного gRPC-канала для каждой «горячей» области нагрузки, что позволяет распараллелить работу по нескольким TCP-соединениям. Второй — использование пула каналов с различными параметрами конфигурации, чтобы избежать повторного использования одного и того же соединения. Оба подхода в теории должны помочь распределить нагрузку и повысить пропускную способность. Экспериментальное внедрение этих рекомендаций выявило, что на практике данные решения не рассматриваются как альтернативные, а скорее представляют собой последовательные шаги одной и той же стратегии. В частности, использование отдельных каналов для каждого работника с дифференцированной конфигурацией (например, добавление специально заданного параметра в аргументах канала) или включение параметра GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL приводит к значительному росту производительности.
В таких условиях достигалась почти шестиразовая прибавка в пропускной способности при одновременном замедлении роста задержек, что свидетельствует о раскрывании потенциала системы и устранении внутрисклиентского узкого места. Результаты экспериментов чётко показали, что сетевые задержки влияют значительно меньше, чем внутренние процессы обработки на клиенте. При тестах с искусственно повышенной задержкой в 5 миллисекунд разница между одноканальными и многоканальными подходами нивелировалась и была заметна только при очень высокой нагрузке. Следовательно, в реальных условиях быстрых дата-центров основное внимание стоит уделить именно управлению каналами и их параметрами, а не сетевой инфраструктуре. Помимо непосредственного создания нескольких gRPC-каналов, важную роль играет правильное распределение потоков и настройка CPU-аффинити.
Использование taskset или аналогичных инструментов, чтобы закрепить процессы и потоки клиентов и серверов на определённых ядрах в пределах NUMA-узлов, улучшает взаимодействие, помогает минимизировать накладные расходы систем планирования и иные вторичные задержки, усиливая общий эффект решения проблемы с узкими местами. Данный кейс подчёркивает, что при проектировании высокопроизводительных систем на базе gRPC нельзя ограничиваться только оптимизацией сетевых параметров и серверных ресурсов. Очень важным становится детальный мониторинг и понимание работы клиентской библиотеки на уровне технологии HTTP/2, ограничения по параллельным потокам, а также возможности правильно конфигурировать и масштабировать клиентские подключения. Такие меры позволяют не только снизить задержки, но и создать масштабируемую архитектуру, способную эффективно работать с высокими нагрузками без потери качества сервиса. В итоге, главным открытием стало осознание того, что традиционные рекомендации по разделению каналов следует рассматривать как этапы единой практики, а не конкурирующие варианты.
Они комбинируются, образуя мощный инструмент для устранения граничных эффектов и повышения общих рабочих характеристик системы. Это знание полезно не только разработчикам, работающим с YDB или аналогичными базами данных, но и всем специалистам, применяющим gRPC для построения распределённых приложений с жёсткими требованиями к латентности и пропускной способности. Применение описанных подходов помогает выявить и устранить скрытые проблемы, заметные только в условиях высокоскоростных сетей и интенсивных нагрузок. В результате разработчики получают надёжный рецепт создания клиентских компонентов, способных раскрывать потенциал серверной части и сетевой инфраструктуры, обеспечивая высокие показатели производительности и стабильности. Продолжающиеся исследования и обмен опытом в сообществе gRPC будут способствовать появлению новых оптимизаций и улучшений, расширяющих возможности современного межсервисного взаимодействия.
Таким образом, чтобы добиться действительно низкой задержки и высокой пропускной способности в системах на базе gRPC, необходимо уделять внимание не только сетевому стеку и аппаратным ресурсам, но и правильно настраивать и масштабировать клиентские соединения. Усвоение этого урока позволит разработчикам создавать более быстрые, масштабируемые и надежные распределённые приложения, отвечающие современным требованиям бизнеса и технологий.