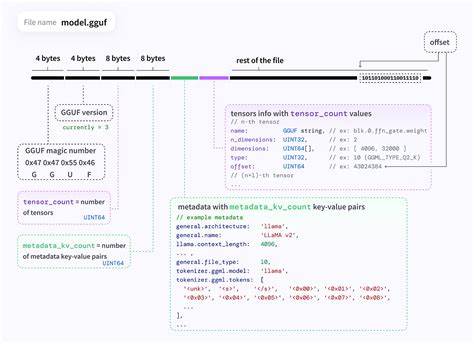
В современном мире больших языковых моделей и искусственного интеллекта повышенное внимание уделяется оптимизации моделей для эффективного использования даже на потребительском оборудовании. Одним из важных направлений является квантование весов нейросетей — процесс уменьшения битовой глубины параметров без значительной потери точности. Среди различных решений особое место занимает GGUF квантование — новый эко-система, которая набирает популярность благодаря своей универсальности и эффективности. GGUF — это не просто формат файла, это целый набор технологий и инструментов, объединенных вокруг оптимизации моделей, основанных на архитектуре LLaMA и схожих с ней. Основные составляющие этой экосистемы включают в себя библиотеку GGML, ориентированную на выполнение тензорных операций для машинного обучения, сервис llama.
cpp, призванный обеспечить эффективный вывод модели, преимущественно на процессорах, а также собственно бинарный формат GGUF, в котором хранятся сжатые, квантованные модели. Главной задачей GGUF квантования является реализация посттренировочного квантования (Post-Training Quantization, PTQ). Этот метод позволяет взять уже обученную модель в высокоточной форме и уменьшить битовую глубину весов — таким образом снижается объем занимаемой памяти и увеличивается скорость работы без необходимости дополнительного дорогостоящего переобучения. Это особенно важно для разработчиков и исследователей, которые стремятся использовать большие языковые модели на обычных настольных компьютерах и ноутбуках. История и происхождение GGUF связана с именем Георги Гергянова, известного активного участника сообщества open source, который совместно с небольшой группой разработчиков создал этот проект как альтернативу более традиционным и академическим подходам, таким как GPTQ, AWQ, QLoRA и QuIP#.
Несмотря на то, что многие из этих методов получили широкое признание в исследовательских кругах, GGUF сделан в первую очередь с прицелом на практичность и открытость. Интересной особенностью GGUF является отсутствие официальной документации. Такой подход обусловлен тем, что команда разработчиков делала ставку на быстрый рост сообщества и добавление признаков через опыт пользователей, а не на научные статьи или объемные руководства. В результате возникла заметная нехватка структурированных, единых источников справочной информации, что и подтолкнуло к созданию неофициальных ресурсов, объясняющих принципы и особенности работы с GGUF. GGUF использует различные методы квантования, включая кванты K-Quants и I-Quants, которые помогают добиться баланса между компрессией и сохранением точности.
K-Quants основаны на квантизации с фиксированным уровнем битности, а I-Quants — на более адаптивных методах, учитывающих важность отдельных весов в итоговой модели. Важным элементом является матрица значимости (Importance Matrix), которая определяет, какие параметры модели требуют более тонкой настройки, а какие можно сжать сильнее без существенного ухудшения качества выдачи. Практическая польза GGUF заключается в упрощении процесса внедрения квантования. Пользователям предоставляется набор команд и инструментов, позволяющих легко переключаться между режимами и экспериментировать с разными вариантами сжатия. Вкупе с высокой производительностью llama.
cpp это позволяет создавать оптимальные конфигурации моделей для разных задач — от генерации текста до сложного анализа данных. Benchmarks, выполняемые сообществом GGUF, демонстрируют заметное снижение требований к оперативной памяти и ускорение инференса без критической потери качества. Особенно это актуально для тех, кто работает на устройствах с ограниченными вычислительными ресурсами — таких как персональные компьютеры среднего класса или даже мобильные устройства. Для эффективного использования GGUF важно понимать основные принципы и реализацию квантования. Общий процесс начинается с подготовки модели в исходном высокоточном формате, после чего применяется посттренировочная оптимизация, снижающая битность параметров.
Дальнейшее хранение и загрузка модели ведется в формате GGUF, который обеспечивает совместимость с экосистемой GGML и llama.cpp. Данный подход хорошо подходит тем, кто хочет сократить затраты на инфраструктуру, не теряя при этом в качестве и точности модели. Это открывает возможности для широкой аудитории — от разработчиков ПО и исследователей до энтузиастов машинного обучения, желающих запустить мощные языковые модели у себя на устройстве. Однако стоит учитывать, что процесс квантования требует аккуратного подхода.
Не все модели и задачи одинаково хорошо подходят для снижения точности, и ошиб aggressive сброс может привести к деградации результата. Поэтому рекомендуется тщательно тестировать квантованные модели в реальных сценариях и опираться на результаты бенчмарков. В будущем GGUF, вероятно, будет развиваться вместе с сообществом, получая новые улучшения и расширения, ориентированные на повышение удобства и качества работы с большими языковыми моделями. Интенсивное развитие open source проектов и поддержка активного сообщества дают надежду, что инструмент будет становиться все более доступным и функциональным. Для тех, кто заинтересован в подробном изучении GGUF, открыты репозитории с бинарными форматами, примерами и непрерывно обновляемой документацией, созданной участниками сообщества.
Активное участие в разработке и обсуждениях помогает поддерживать проект на пике современных технологий и адаптировать его под новые требования рынка. Таким образом, GGUF квантование является важным шагом в развитии технологий оптимизации больших языковых моделей, позволяя обрести баланс между качеством, скоростью и ресурсами. Эта технология открывает новые горизонты для внедрения ИИ в разнообразные сферы, делая их более доступными и экономичными.