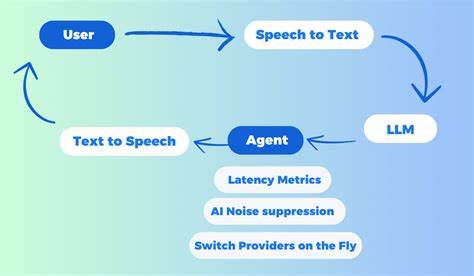
В современном мире искусственный интеллект стремительно меняет способы коммуникации и обработки информации. Одним из самых впечатляющих достижений является возможность вести разговоры с крупными языковыми моделями (LLM) не просто через текст, а голосом, в реальном времени. Именно такую технологию предлагает система Unmute — уникальной продукт, разработанный компанией Kyutai Labs, которая позволяет заговорить с текстовыми ИИ, используя собственный голос, и получать ответ также в звуковом формате без ощутимой задержки. Unmute основан на синергии нескольких мощных компонентов: моделей преобразования речи в текст (Speech-to-Text), текстовых языковых моделей и технологий преобразования текста в речь (Text-to-Speech). Вся цепочка работает так, что голос пользователя мгновенно переводится в текст, затем ИИ генерирует осмысленный ответ, который сразу же озвучивается обратно пользователю.
При этом весь процесс заточен на минимизацию задержек, что делает коммуникацию максимально приближённой к живому разговору. Одним из ключевых преимуществ Unmute является универсальность. Система совместима с любой текстовой языковой моделью, которую предпочитает пользователь. Несмотря на то что по умолчанию Unmute использует такие мощные модели как Mistral Small 3.2 24B или Gemma 3, разработчики предоставляют возможность интеграции внешних решений, включая популярные облачные сервисы от OpenAI или локальные модели через VLLM.
Это позволяет гибко адаптировать инструмент под разные задачи — от личного помощника до бизнес-бота. Реализация Unmute — это сложная архитектура из множества взаимосвязанных сервисов. Работа начинается с веб-интерфейса, где пользователь запускает сессию и подключается к бекенду по протоколу websocket. Через этот канал аудиопоток поступает к модулю STT, который в режиме реального времени транскрибирует речь. Как только система фиксирует паузу в голосовых данных, в работу включается языковая модель, усиливая её запросом полученный текст.
Ответ, приходящий от ИИ в текстовом виде, тут же направляется в модуль TTS и синтезируется в аудиосигнал для пользователя. Оптимизация скорости является приоритетом разработчиков Unmute. Особое внимание уделено распределению нагрузки между GPU-ускорителями. На продакшене сервисы для распознавания речи, генерации ответов и синтеза речи часто работают параллельно на отдельных видеокартах. Благодаря этому удаётся достичь минимальной задержки — в среднем менее полсекунды на формирование озвученного ответа, что существенно превышает по качеству и ощущениям большинство аналогов.
Установка и использование Unmute относительно доступны для специалистов с базовым опытом работы с Docker и GPU-серверами. Хотя система требует наличие видеокарты с поддержкой CUDA и как минимум 16 ГБ видеопамяти, развёртывание рекомендуется проводить через Docker Compose — это упрощённый способ управления сложным набором микросервисов. При необходимости возможно выполнение Unmute без Docker, однако это значительно осложняет рутину из-за необходимости тщательной настройки зависимостей. Интересно отметить, что разработчики оставили открытой возможность масштабирования решения. Например, можно использовать технологию Docker Swarm для запуска нескольких инстансов Unmute на кластере из десятков GPU, что особенно важно для бизнес-задач с высокими требованиями к параллельной обработке голосовых запросов и высокой доступности.
Обеспечение безопасности и корректное управление доступом — ещё один аспект, продуманный в Unmute. Интеграция с Hugging Face Hub предполагает использование токенов доступа с минимальными необходимыми правами, что помогает защитить аккаунты и предотвратить несанкционированное использование моделей и данных. Кроме того, для взаимодействия с внешними API можно гибко настраивать URL и ключи доступа, давая возможность выбирать между локальными и облачными LLM. Не менее важна и пользовательская составляющая интерфейса Unmute. Веб-клиент построен на Next.
js и использует websocket-протокол, который отчасти повторяет OpenAI Realtime API, расширяя и упрощая коммуникацию между фронтендом и бэкендом. Благодаря удобным сочетаниям клавиш можно включать субтитры или активировать режим разработчика для диагностики, а конфигурация голосов и персонажей осуществляется с помощью простых YAML-файлов, что позволяет легко адаптировать голосового помощника под конкретные нужды или настроить различные роли с уникальными характерами и стилями речи. Важным направлением развития системы является поддержка интеграции вызова внешних инструментов прямо из диалога. Подразумевается, что логика управления такими вызовами будет вынесена на слой LLM-сервера, что сделает процесс невидимым для основного движка Unmute и позволит расширять возможности системы за счёт специализированных сервисов, например, для получения актуальной информации, генерации медиа или взаимодействия с базами данных. Unmute не просто экспериментальный проект — за ним стоит сообщество с более чем 900 звёздами на GitHub, регулярной поддержкой и обновлениями.





![Aardvark'd: 12 Weeks With Geeks [video]](/images/B9251125-7858-4D2C-B49F-637C1265B0B0)

