gRPC — один из самых популярных фреймворков для реализации удалённого вызова процедур, широко используемый в современных распределённых системах и микросервисной архитектуре. Благодаря надёжности и высокой производительности, gRPC завоевал доверие разработчиков по всему миру. Однако в реальных условиях эксплуатации иногда можно столкнуться с неожиданными ограничениями, которые могут значительно влиять на скорость обработки запросов и качество взаимодействия сервисов. Одним из таких сюрпризов оказалась узкая точка на стороне клиента gRPC, проявляющаяся в сетях с низкой задержкой. Проблема возникла в среде компании YDB, где gRPC используется для предоставления API распределённой SQL-базы данных.
Несмотря на мощность серверных узлов и высокоскоростные каналы передачи данных с низкой латентностью, наблюдалось ухудшение пропускной способности и рост клиентской задержки при уменьшении размера кластера. Чем меньше было серверных нод, тем менее эффективно клиент мог загружать систему, а внутри кластера простои ресурсов росли. Такая ситуация полностью противоречила ожиданиям и требовала тщательного расследования. Внимательный анализ и собственный микро-бенчмарк gRPC, написанный на C++ и использующий последние версии фреймворка, позволили выявить, что основным узким местом являются особенности работы реализации gRPC на стороне клиента. Несмотря на то что соединение между сервером и клиентом проходят по высокопроизводительному HTTP/2, сама архитектура граничного узла клиента накладывает жесткие ограничения на количество параллельно обрабатываемых запросов.
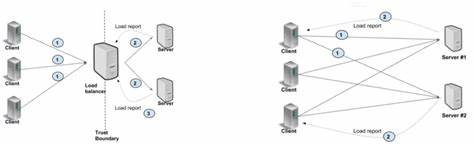
Внутренне gRPC организует поток RPC-запросов через каналы (channels), которые в свою очередь используют HTTP/2 TCP-соединения с поддержкой мультиплексирования. Каждое TCP-соединение способно обрабатывать ограниченное число одновременных потоков — как правило, около 100. Если число активных запросов превышает этот предел, новые запросы оказываются в очереди и не могут быть немедленно отправлены на сервер, вызывая задержки и снижая общую пропускную способность. В чтении технической документации традиционно предлагаются два основных способа решения этой проблемы: создавать отдельные каналы для высоконагруженных областей приложения или использовать пул каналов, чтобы распределить трафик между несколькими TCP-соединениями. В практике YDB оба эти пути оказались частями одного общего решения.
Реализация с выделением отдельного канала для каждого рабочего узла клиента с уникальным набором параметров канала или использование опции GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL позволило убрать узкое место и добиться как прироста пропускной способности, так и снижения задержек. Таким образом стало ясно, что ключом является суммарное распределение трафика по разным TCP-соединениям без разделения нагрузки на одном канале. Для проверки был разработан простейший микро-бенчмарк, который исполнял функцию «ping» с нулевой нагрузкой на полезный payload, чтобы фокусировать внимание исключительно на архитектуре транспортного уровня и gRPC. Тестирование проводилось на двух мощных вычислительных узлах, соединённых 50-гигабитным сетевым каналом с минимальными пинг-временами в диапазоне микросекунд. Результаты показали, что при использовании одного канала с подачей множества параллельных запросов пропускная способность возрастала далеко не линейно, а задержки начинали стремительно расти даже при малом числе одновременно отправленных запросов.
Захват и анализ сетевого трафика продемонстрировал, что ограничение источника задержек находится именно на стороне клиента, а не связан с сетевой транспортной прослойкой, задержками или перегрузками сервера. Между отдельными запросами наблюдались очереди в десятки сотен микросекунд без активной передачи данных. Переключение на многоканальную модель граничного клиента позволило добиться существенного увеличения числа обработанных запросов в секунду и одновременно удержать пиковые задержки на низком уровне. При повторении же тех же тестов в сетях с высокой латентностью, порядка нескольких миллисекунд, проблема становилась менее выразительной. В таких условиях возможность использовать один канал уже не являлась критичной, а выгоды от использования множества каналов были меньшими, что логично — задержки сети доминировали над задержками клиентской обработки.
Данный опыт даёт важные рекомендации для инженеров и разработчиков, занимающихся построением высокопроизводительных распределённых систем с применением gRPC. В условиях, где сеть имеет минимальную задержку и высокую пропускную способность, крайне важно уделять внимание внутренним спецификациям gRPC и его ограничению по числу параллельных потоков на TCP-соединение. Создание индивидуальных каналов и использование разных параметров для их конфигурации помогает избежать внутренней конкуренции и блокировок, тем самым раскрывая весь потенциал высокоскоростных сетей. Стоит отметить, что пока что данное решение проверено на примерах кода на C++ и Java, но есть основания полагать, что подобное поведение характерно для большинства реализаций gRPC и применимо во многих программных средах. Инженеры YDB приглашают сообщество к обсуждению и совместной работе над дополнительными оптимизациями, а также предоставляют открытый исходный код микро-бенчмарка, что поможет разработчикам проводить аналогичные тесты и улучшать производительность своих систем.
В конечном итоге, открытие узкого места клиента gRPC в условиях низкой задержки — это важный шаг к росту эффективности распределённых баз данных и других сервисов, построенных на микросервисной модели. Своевременное понимание особенностей работы транспорта и памяти внутри клиента позволяет уже сегодня создавать более быстрые и отзывчивые приложения, способные отвечать на потребности самых взыскательных пользователей и нагрузок. В будущем ожидается появление ещё более тонких настроек и методов оптимизации, которые помогут добиться новых рекордов пропускной способности и устойчивости систем.