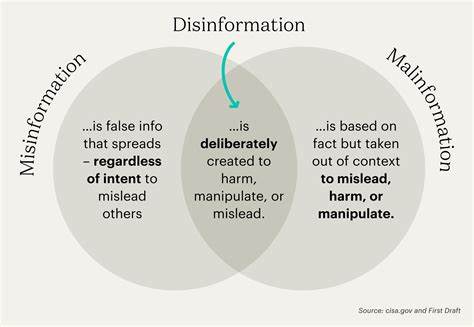
В последние годы искусственный интеллект и особенно большие языковые модели стремительно развиваются, достигнув невероятных высот по количеству используемых вычислительных операций и объему данных для обучения. Усиленное обучение (Reinforcement Learning, RL) утвердилось как одна из ключевых методик, способствующих созданию моделей с непревзойденной способностью к рассуждению, адаптации и решению сложных задач. Однако переход к масштабированию RL до уровня 10^26 операций с плавающей запятой (FLOPs) предъявляет новые вызовы, требующие свежего взгляда и инновационных подходов. Обсудим, каким образом сейчас развивается масштабирование RL, почему традиционные методы сложны, и какую роль играет идея объединения RL с предсказанием следующего токена для обучения моделей на масштабах всей сети Интернет. Истоки масштабирования искусственного интеллекта связаны с применением обучения с учителем на предобученных моделях, способных воспринимать огромные объемы текстов, изображений и других данных.
Модели обучались на миллиардных токенах информации, проявляя хорошие результаты в различных задачах. Несмотря на успехи предобучения, становится очевидным, что одна лишь масштабность — не залог безграничного прогресса. Усиленное обучение предлагает учить модели через интерактивные процессы, где вместо простого повторения обучения по готовым данным модель получает вознаграждения за правильные решения, тем самым развивая навыки рассуждения и адаптации к новым ситуациям. Основной трудностью при масштабировании RL является сложность организации вычислительного процесса, в отличие от предобучения, где обучение сильно дискретизировано, а поток обработки данных сравнительно однороден. При RL обучающий процесс включает этапы моделирования рассуждений, генерации промежуточных ответов и оценки корректности через функции вознаграждения.
Эти этапы требуют значительных ресурсов на генерацию и проверку, что накладывает жесткие ограничения на скорость обучения и его масштаб. Особенно затруднительно реализовать эти задачи в масштабах, приближенных к 10^26 FLOPs. Ключевой фактор успешного обучения через RL — наличие надежных и автоматизированных средств оценки правильности результатов. В научных и технических областях, таких как математика, программирование и некоторые типы головоломок, эта проверка более очевидна и может быть сведена к запуску тестов или сопоставлению с эталонными ответами. Однако для огромного спектра человеческих знаний и творческих задач очевидных «верификаторов» не существует, что существенно ограничивает области применения RL с проверяемой наградой.
В стремлении преодолеть эти ограничения, одна из наиболее многообещающих идей состоит в объединении обучения с RL и классического обучения с помощью предсказания следующего токена, как в традиционных языковых моделях. Предсказание следующего токена подразумевает прогнозирование следующего элемента текста на основе предшествующего контекста и является естественной формой обратной связи, которую можно использовать в качестве своего рода функции вознаграждения. Такое объединение дает возможность масштабировать RL на разнообразные и обширные интернет-данные, используя принцип понятия «верифицируемости» на уровне языкового моделирования, без необходимости разработки сложных доменно-специфичных проверяющих систем. Этот подход позволяет применять RL как способ обучения рассуждению и самокоррекции посреди огромного массива неструктурированных данных. Модель может генерировать внутренние «мысли» или цепочки рассуждений, которые затем оцениваются через качество предсказания будущих токенов, тем самым создавая динамичное поле для обучения.
Такая методика повышает возможности модели использовать собственный опыт и саморефлексию для формирования более точных и обоснованных ответов, что является важным преимуществом перед традиционными методами предобучения. Несмотря на то, что идея совместить RL с предсказанием следующего токена кажется естественной и перспективной, технические и инженерные вызовы остаются огромными. Во-первых, генерация токенов в режиме обучения требует значительно больше ресурсов, чем простое вычисление ошибок предсказаний, особенно при масштабах качества и объема токенов, сопоставимых с глобальным интернет-пространством. Во-вторых, необходимо тщательно формализовать функции вознаграждения, которые смогут заставлять модели многоразово генерировать обоснованные и последовательные рассуждения, а не случайные или поверхностные ответы. На уровне инфраструктуры сложность масштабирования RL затрагивает аспекты оптимизации вычислений, ускорение генерации, эффективное распределение нагрузки между серверами и обработку параллельных сред обучения.
Современные серверы, такие как NVIDIA DGX B200, способны обеспечивать порядка 10^17 FLOPs, но текущие RL-системы не используют таких ресурсов в полной мере. Это связано с ограничениями в управлении вычислительными процессами, медленным исполнением проверяющих функций и генерацией токенов, что требует разработки новых инженеринговых решений и программного обеспечения с высокой степенью параллелизма и адаптивности. Кроме того, существует проблема выбора и создания обучающих сред и задач для RL. Модели необходимо одновременно обучаться в различных доменах и навыках, от математики и программирования до естественного языка и творческого письма. Комбинация этих навыков требует точной настройки тренировочных стратегий, экспериментов с различными типами обратной связи и механизмом объединения моделей для получения оптимальных результатов.
Эта задача сама по себе остается открытой и нуждается в систематическом научном подходе. Перспективной областью исследований выступает развитие методологий, позволяющих системе самооцениваться и производить самостоятельный отбор примеров с высоким качеством обучения. Применение метрик, основанных на уверенности и энтропии генерируемых токенов, позволяет выделять наиболее информативные фрагменты и мотивировать модель к более глубокому «размышлению» во время обучения. Такая техника способствует формированию более устойчивых логических цепочек и повышает эффективность использования ограниченных вычислительных ресурсов. Подводя итог, масштабирование усиленного обучения до уровня 10^26 FLOPs — амбициозная задача, которая имеет потенциал существенно продвинуть искусственный интеллект.
Интеграция RL с подходом предсказания следующего токена открывает новые горизонты в обучении моделей рассуждать на основе обширных и разнообразных данных с минимальными ограничениями по области применения. Важнейшим условием успеха станут значительные инженерные инновации, разработка адаптивных сред обучения и глубокое понимание нюансов в формировании вознаграждений внутри обучающих алгоритмов. Текущий этап развития представляет собой переход от классических методов масштабирования, основанных на увеличении объема данных и параметров моделей, к более интеллектуальным стратегиям, где модели учатся эффективно применять доступные вычислительные ресурсы для генерации качественных и обоснованных ответов. По мере решения описанных проблем можно ожидать появления новых поколений reasoning-моделей, способных решать широкий спектр сложных задач и вносить качественный вклад в разнообразные сферы человеческой деятельности. Таким образом, будущее усиленного обучения связано не просто с компенсированием вычислительной мощности, а с эффективным ее применением через сочетание непрерывного обучения, самоанализа и генерации качественных рассуждений.
В этом направлении уже ведутся активные исследования и эксперименты, которые могут радикально изменить подходы к обучению искусственного интеллекта, вывести отрасль на совершенно новый уровень и приблизить создание моделей с человеческим или даже превосходящим интеллектом.