В современную эпоху искусственного интеллекта большие языковые модели (LLM) стали неотъемлемой частью разнообразных приложений в области обработки естественного языка. Их способность понимать и генерировать текст высокого качества позволила кардинально изменить подход к автоматизации задач в бизнесе, науке и повседневной жизни. Однако процесс адаптации таких моделей к конкретным задачам зачастую требует значительных вычислительных ресурсов и времени. В связи с этим появляется необходимость разработки более эффективных методов настройки, которые позволят добиться высоких результатов с меньшими затратами. Одной из перспективных инноваций в этой области стала методика Low-Rank Multiplicative Adaptation, или LoRMA, представляющая эволюцию популярного подхода Low-Rank Adaptation (LoRA).
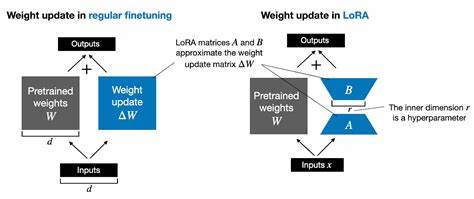
LoRA завоевала широкое признание благодаря использованию низкоранговых приближений для обновления весов модели путём добавления специальных изменений к исходной матрице весов. Такой подход позволяет существенно сократить количество параметров, требующих обучения, и уменьшить вычислительную нагрузку. Тем не менее, он опирается на аддитивные (сложение) преобразования, что накладывает определённые ограничения на выразительность обновлений и эффективность адаптации. LoRMA предлагает перейти от аддитивных операций к умножению матриц, открывая тем самым новый простор для более гибких и мощных обновлений в пространстве весов языковой модели. Вместо того чтобы просто добавлять поправки к исходным параметрам, LoRMA осуществляет умножение исходной матрицы весов на произведение низкоранговых матриц и скалярного коэффициента, что способствует более выразительным трансформациям.
Однако прямое умножение сопряжено с такими вызовами, как рост вычислительной сложности и ограничение ранга итоговых преобразований, поскольку произведение матриц не может иметь ранг выше минимального из рангов множителей. Чтобы преодолеть эти препятствия, разработчики метода LoRMA предложили ряд оригинальных решений. Одной из ключевых идей является перестановочная инфляция ранга, которая достигается путём циклической перестановки строк матриц. Такой метод позволяет повысить ранг итогового произведения, фактически расширяя пространство выражаемых преобразований без увеличения вычислительной нагрузки или потери градиентной информативности. Еще одной инновационной стратегией стала аддитивная инфляция ранга, вдохновлённая техниками из области ридж-регрессии.
В этом случае к произведению низкоранговых матриц добавляется единичная матрица, что обеспечивает начальную инициализацию с единичным преобразованием и позволяет сохранить полноранговую структуру обновлений на протяжении обучения. Эти подходы не только решают вопрос сложности модели и её устойчивости при обучении, но и предоставляют широкие возможности для гибкой подстройки параметров без потери качества. В широком спектре экспериментов, проведённых на различных языковых моделях разных размеров — от RoBERTa и GPT-2 до более масштабных Gemma-2B и LLaMA3-8B — LoRMA демонстрирует конкурентоспособные и в ряде случаев превосходящие результаты по сравнению с классическими методами, такими как LoRA и её вариации. Особенно примечательна высокая скорость сходимости новых моделей, что связано с более богатой параметрической структурой умножающих преобразований. Показано, что благодаря этому достигается более быстрое стабилизирование обучения и снижение потерь уже на начальных этапах, что существенно экономит ресурсы и ускоряет выход модели на необходимые показатели.
Дополнительный анализ подтверждает, что наличие стратегий инфляции ранга является критичным для успешного обучения — в отсутствие этих техник производительность LoRMA заметно снижается. В сравнении с аддитивными обновлениями LoRA, LoRMA достигает более высокой экспрессивности финальных весов, сохраняя при этом большое сходство в результирующих изменениях, что указывает на способность модели эффективно захватывать необходимые адаптации при помощи множительных подходов. Подводя итог, можно отметить, что Low-Rank Multiplicative Adaptation становится значительным шагом вперёд в области параметрически эффективной тонкой настройки больших языковых моделей. Он сочетает в себе математическую строгость и практическую применимость, позволяя эффективно адаптировать модели под задачи последнего времени. По мере развития искусственного интеллекта и усложнения архитектур LLM, такие инновации помогут создавать более производительные и адаптивные системы.
Дальнейшие исследования в области комбинирования LoRMA с уже существующими улучшениями LoRA обещают ещё более высокую эффективность и масштабируемость решений. Этот метод служит отличным примером того, как глубокое понимание свойств матриц и линейной алгебры способно привести к прорывным результатам в машинном обучении и обработке естественного языка.