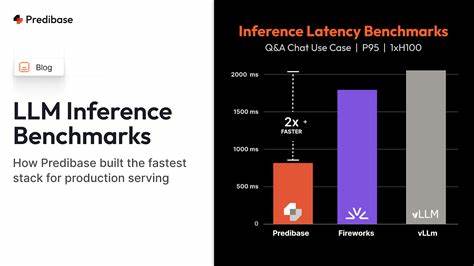
В последние годы большие языковые модели (LLM) стали неотъемлемой частью многих современных технологий искусственного интеллекта. Они лежат в основе чат-ботов, автоматического перевода, систем рекомендаций и множества других приложений. В связи с этим критически важной задачей становится не только обучение таких моделей, но и их быстрый и эффективный инференс — процесс генерации ответов или результатов на основе обученной модели. Именно для решения задач объективной оценки производительности инференса был создан LLM Inference Benchmark Hub — инновационная платформа, предоставляющая разработчикам и исследователям инструменты для тестирования, сравнения и мониторинга различных LLM с точки зрения скорости, качества и рентабельности их работы. Понимание необходимости объективного бенчмаркинга Inferece любого ИИ-приложения высоко ценно для оптимизации ресурсов и обеспечения высококачественного пользовательского опыта.
LLM Inference Benchmark Hub выступает в роли универсального центра для анализа. Он предоставляет стандартизированный набор тестов и метрик, которые позволяют сравнивать модели LLM разных архитектур и производителей вне зависимости от платформы исполнения. Платформа работает с огромным количеством распространённых языковых моделей, включая GPT, BERT, T5, и многих других, давая возможность понять их реальные преимущества и слабые стороны. Одним из ключевых преимуществ LLM Inference Benchmark Hub является его открытость и простота использования. Пользователи могут войти через учетную запись GitHub, что облегчает процесс доступа и интеграции с окружающей экосистемой разработчиков.
Сервис позволяет запускать инференс-тесты в режиме реального времени, получая детальную аналитику по скорости обработки запросов, используемой памяти, энергопотреблению и другим важным параметрам. Кроме того, платформа регулярно обновляется и поддерживается сообществом специалистов по ИИ, что гарантирует актуальность данных и появление новых моделей и алгоритмов. Помимо базовых тестов, LLM Inference Benchmark Hub предлагает гибкие инструменты для настройки и запуска кастомных сценариев инференса, что особенно полезно для крупных компаний и исследовательских лабораторий, которым важно проверить модели в специфических условиях или с нестандартными типами входных данных. Такой подход позволяет максимизировать пользу от тестирования и существенно улучшить производительность внедряемых решений. Важной частью платформы является раздел, где пользователи могут поделиться результатами своих исследований и экспериментов, создавать свои рейтинги и обзоры.
Это способствует формированию сообщества профессионалов и энтузиастов, которые совместно работают над улучшением технологий ИИ и обменом знаниями. Благодаря LLM Inference Benchmark Hub разработчики получают возможность не просто выбрать модель по популярности или заявленной эффективности, а опираться на реальные, объективные и воспроизводимые данные. В итоге это приводит к созданию более быстрых, экономичных и точных AI-продуктов, которые могут успешно масштабироваться и адаптироваться под разные задачи. На фоне растущей конкуренции и постоянного появления новых архитектур LLM, наличие единой платформы для тестирования становится критическим фактором успеха. Она помогает сэкономить время и ресурсы, снижая риски при внедрении новых моделей в продукты.







